史上最全图形学面经(带连接版)
本文最后更新于:1 分钟前
介绍一下渲染管线,三维坐标如何变成屏幕坐标,有哪些变换?
渲染管线:图形渲染管线详细梳理 - 知乎 (zhihu.com)
GPU渲染管线之旅|03 图形管线概览及GPU中顶点处理 - 知乎 (zhihu.com)
MVP变换:games101学习笔记02-MVP变换p4 - 哔哩哔哩 (bilibili.com)
下面以Vulkan官网给出的适配渲染管线为例,结合OpenGL官方手册简述每个pass的流程:
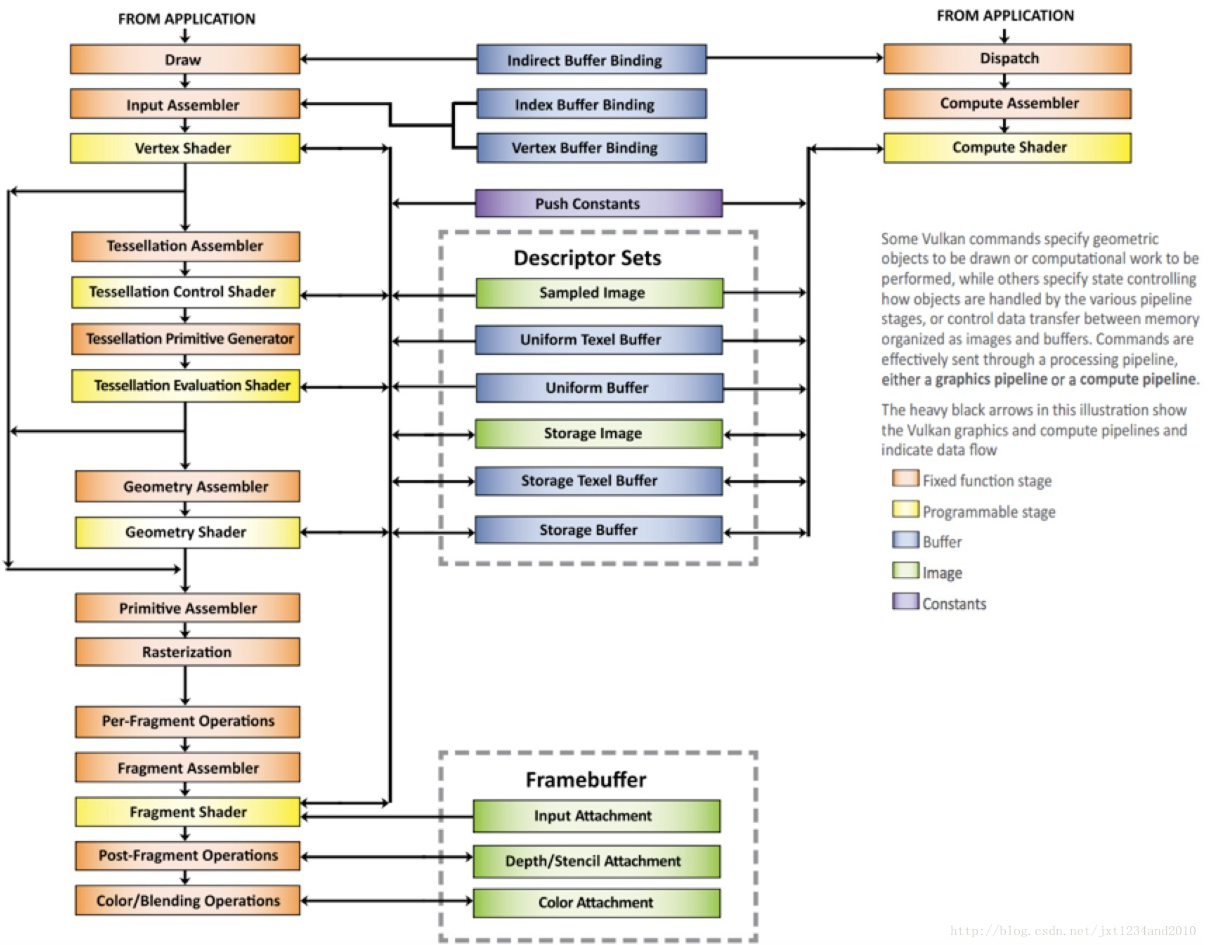
Input Assember输入装配:这个主要是在CPU端完成的,目的是确认哪些mesh资源和相关的绑定需要传入渲染管线进行渲染。主要进行CPU Culling、mesh的选择与分类(例如static、dynamic、instance等)、资源的申请(例如光源列表、纹理资源等)等,同时获取渲染状态信息,例如前向或者延迟管线、各种宏开关、资源绑定状态、视口等等,最终得到三类信息: DescriptorSet(纹理和常量)、Pipeline(着色器和状态)和Buffer(顶点数组)。将这三类信息通过DrawCall传递给GPU,下面进行GPU的渲染管线流程:
Vertex Shader顶点着色器: 顶点着色器是对每个vertex处理的,没有图元属性,主要进行逐顶点的MVP变换、法线坐标变换、纹理坐标生成等等,还可以做逐顶点光照
Hull Shader外壳着色器:设置LOD标志点等进行曲面细分的基本参数。Hull Shader的代码有两个阶段,一个阶段是“control point phase”,用于告知硬件控制点数据;一个阶段是“patch constant phase”,用于告知细分器(Tessellator)一些常数信息,比如细分次数。
Tessellator曲面细分器:曲面细分阶段,根据标志点生成更多顶点。一般来说曲面细分策略是完全在硬件上封装的。
Domain Shader域着色器:曲面细分的数据结果会由Domain Shader进行处理,Domain Shader会将新插入的顶点,根据采样的高度图来移动顶点的位置,这样会形成地形的高低起伏感。
Geometry Shader几何着色器: 可以操控整个几何结构,进行顶点变换、生成新的顶点。主要用来做几何的放大缩小、生成新几何体等等。例如笔刷工具中的foliage植被系统、水体的波动等。Geometry Shader会将移动过位置的顶点的顶点数据再计算一遍,比如纹理的UV坐标、以及需要传递到像素着色器的数据等等。
Vertex Post-Processing and Primitive Assembler顶点后处理:主要是为光栅化准备数据。逐图元的clip space culling,具体的图元剔除策略与硬件相关,默认的一般为生成新的顶点组装为新的三角形。其次进行视口变换,确定屏幕坐标和SV_Position。然后将顶点组装为图元。在OpenGL手册上,mesh的背面剔除也是在这里发生的。
Rasterization光栅化 :光栅化没什么好说的,网上相关的资料都说烂了,大意就是根据扫描线算法计算每个三角形覆盖了哪些像素,计算三角形三个顶点在三角形内每个像素上的重心插值数据。
Pixel Shader像素着色器 :也叫Fragment Shader,主要功能是着色。将光栅化的结果例如深度、法线、abedo等属性写到每个像素上,可以输出多张texture。
Post Fragment Operations输出合并:主要是进行各种test,按先后顺序是裁剪测试、透明度测试、模板测试、深度测试、透明度blend,最后以各种逻辑合并到Framebuffer中。
单独提一嘴,Compute Shader是个伟大的发明,它不在默认的渲染管线中,但是却可以直接调用硬件计算单元对给定资源按照给定的方式进行多线程计算。
ndc是什么,坐标范围?
延迟渲染管线和前向渲染管线有什么区别?各有什么优劣?
介绍一下Shadowmap。除此之外还有有哪些阴影处理算法?
图形学基础 - 阴影 - ShadowMap及其延伸 - 知乎 (zhihu.com)
UE5 的VSM+SMRT:UE5 Virtual Shadow Map之SMRT算法 - 知乎 (zhihu.com)
软阴影可以怎么做?
PT PCF PCSS VoxelConetracing步进 VSM VSSM MSM
实时阴影(二) CSM, PCSS与SDF Soft Shadow - 知乎 (zhihu.com)
vssm需要额外存储什么数据?vsm有什么问题?漏光的原因是什么?
在生成shadowmap的时候生成一张深度的平方,然后计算出均值和平方的均值的mipmap,或者保存深度和和深度平方和用来计算SAT,通过这俩来计算方差,进而计算切比雪夫。

VSM会导致漏光。切比雪夫的成立条件是像素点深度d要大于卷积核内的平均深度davg,当像素点深度小于的时候,就默认没有遮挡。但是在物体边缘位置,可能会在卷积核内有几个深度特别大,导致davg很大,进而造成漏光。
CSM是怎么做的?
半透明效果是如何实现的
【2022.11.21更新】一篇文章能不能说清楚半透明渲染 - 知乎 (zhihu.com)
半透明最重要的是排序,严格从后往前渲染。但是有论文可以通过傅里叶变换省略排序过程
反射探针是否了解?
[Unity/URP学习]反射探针(Reflection Probe)_unity反射探针_はかい_Phantom的博客-CSDN博客
UE的streaming?
earlyZ和preZ的区别与联系?
虚幻4渲染编程(Shader篇)【第十四卷:PreZ And EarlyZ In UE4】 - 知乎 (zhihu.com)
多个光照探针之间如何进行blend?
DDGI中的混合光照模型:
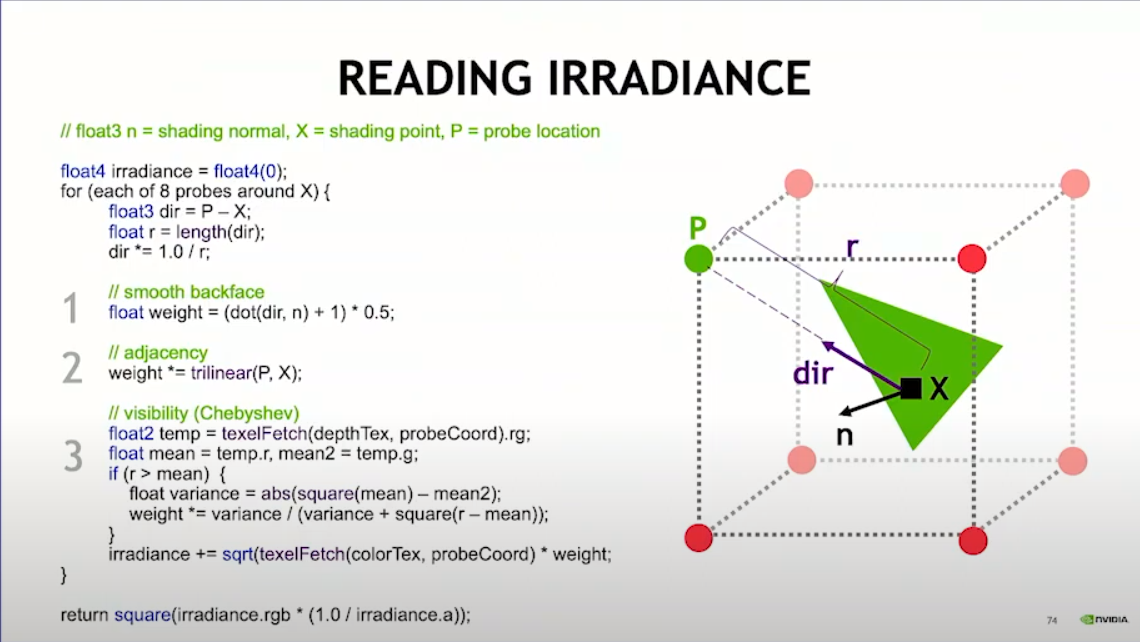
对于任意一个着色点X,依次统计该点周围八个probe的贡献:
step1:环绕照明权重的经典做法,平滑了背部的过渡,防止一个在背面的物体影响到该表面的正面着色
step2:两点之间的三线性差值,离得越近权重越大
step3:可见性计算。采用计算出的径向深度贴图。首先在该方向进行纹理采样,得到该方向的径向距离和平方。如果实际距离r大于纹理中记录的径向距离,则采用切比雪夫不等式来计算权重;若小于记录的径向距离,则权重为1,这样可以尽量避免漏光
为了近似拟合八个方向的irradiance,在分别计算每个方向时sqrt一下,最终整合时再square一下。
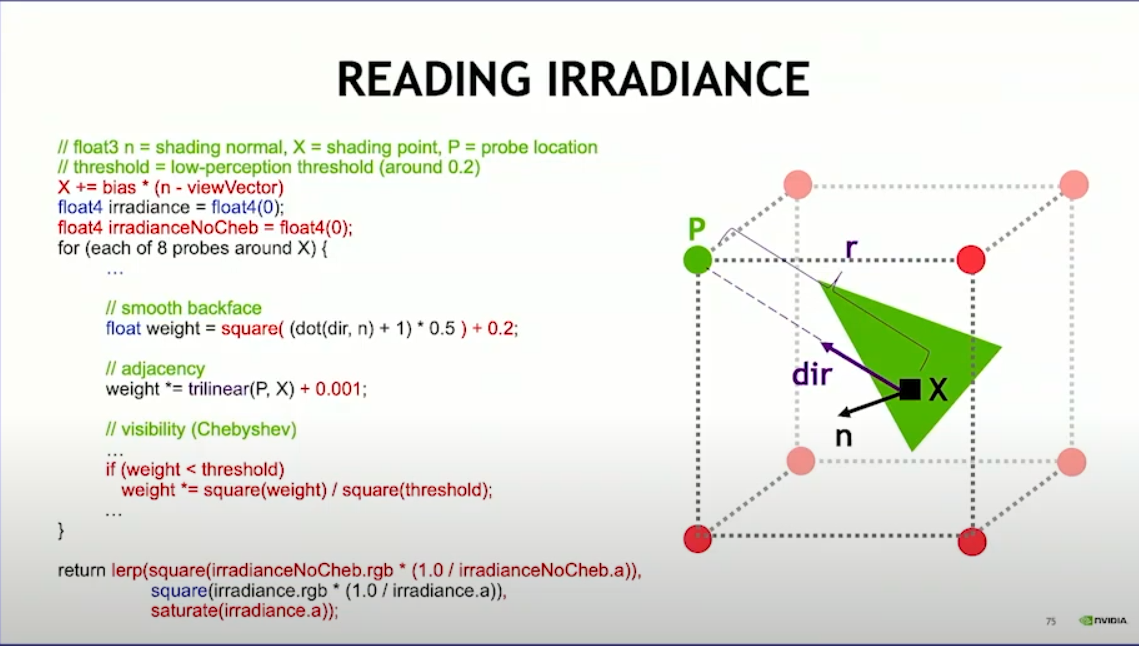
实际上,为了减少计算中可能导致的问题(probe在墙内会完全变黑),需要在每个weight上加一个适当的偏移,以确保不会完全淘汰任意一个probe。当极限情况,即周围八个probe都不可见时,我们会回退到之前无切比雪夫权重的情况,这样做虽然不合理,但是效果会更好。
如果SSGI使用柱状投影图,会有什么问题?
会错误判断遮挡。
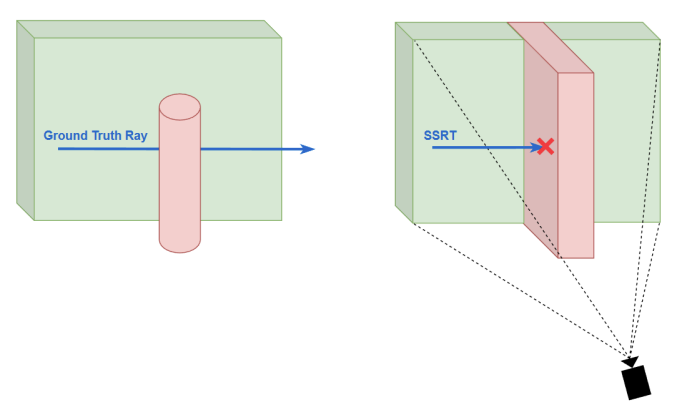
通常限定hit depth和depth之间如果差值太大返回uncertain。
Tile-Based光栅化?
说一说蒙特卡洛的原理?
蒙特卡洛是一种求解定积分的数值方法。几何上就是通过无数个矩形去近似模拟积分区域的面积。 \[ \int f(x) \mathrm{d} x=\frac{1}{N} \sum_{i=1}^N \frac{f\left(X_i\right)}{p\left(X_i\right)} \quad X_i \sim p(x) \]
不用蒙特卡洛怎么近似计算渲染方程?
IBL贴图近似。split sum
PRT SH预计算
GPU如何处理导数?
虽然片元着色器可以完成很多重要效果,但它的局限在于,它仅可以影响单个片元。也就是说,当执行片元着色器时,它不可以将自己的任何结果直接发送给它的邻居们。有一个情况例外,就是片元着色器可以访问到导数信息(gradient,或者说是derivative)。 GPU能够处理导数信息的原因是因为GPU需要通过对纹理进行mipmap预处理减少带宽,而mipmap的等级涉及导数运算。于是GPU将32个像素线程将会被分成一组,或者说8个2x2的像素块,这是在像素着色器上的最小工作单元,以此来计算ddx/ddy。
大世界场景需要注意哪些问题?
世界坐标精度:UE5中引入TranslatedWorldPosition,在world position的基础上加上了相机坐标的偏移
场景管理:大世界空间通常包含大量的物体和复杂的几何形状,因此需要使用高效的场景管理技术来管理场景数据。例如,可以使用空间分割技术(如八叉树、BVH等)来加速场景遍历和渲染。UE5强制使用世界分区
纹理管理:在大世界空间中,纹理通常需要使用大量的内存和带宽,因此需要使用高效的纹理管理技术来减少内存和带宽的使用。例如,可以使用纹理压缩技术(如BC、ETC等)来减少纹理的大小,或者使用纹理流(Texture Streaming)技术来动态加载和卸载纹理。多级LOD或UE5中的nanite技术
光照和阴影:在大世界空间中,光照和阴影通常需要考虑更多的因素,例如远距离的光照、大范围的阴影等。因此,需要使用高效的光照和阴影技术来处理这些问题。例如,可以使用预计算光照(Precomputed Lighting)技术来加速光照计算,或者使用级联阴影映射(Cascaded Shadow Maps)技术来处理大范围的阴影。
远景渲染:在大世界空间中,远景通常需要使用特殊的渲染技术来处理,例如大气散射、云层渲染等。这些技术需要考虑更多的物理因素和视觉效果,因此需要使用更高级的算法和数据结构来实现。
性能优化:在大世界空间渲染中,性能优化是非常重要的。需要使用高效的渲染技术和算法来提高渲染效率,并使用合适的硬件和软件配置来优化渲染性能。例如,可以使用GPU Instancing、Batching等技术来减少渲染调用次数,或者使用多线程渲染技术来提高渲染效率。或者合并Mesh减少Draw Call。
除了BVH以外还有哪些空间划分方式?各有什么适用范围?
空间数据结构(四叉树/八叉树/BVH树/BSP树/k-d树) - KillerAery - 博客园 (cnblogs.com)
ray tracing pipeline了解吗?
mobile移植时有哪些问题?
1、vulkan PC端的一些扩展或者格式,到了移动端不一定有,需要检查设备对这些扩展或者格式的支持情况,用vulkan capability viewer这个app可以检查 2、有可能会闪烁,需要开vulkan synchronization validation去检查,一般是加pipeline barrier 3、有些手机端的优化手段可以利用,比如16位的half float运算,arm芯片专属的afbc
项目在UE各个版本迁移时有哪些问题?
Render Target的对齐问题。可能新版本的RT发生变动,和项目对于引擎的修改冲突
某些函数的写法被淘汰,需要更新
新特性引入,例如UE5的大世界坐标系统
合并时和项目代码的冲突问题
有关注过显卡迭代过程中加入了哪些新特性吗?
indirect 的 specular该怎么做?
对于实时GI来说,1次bounce的specular可以通过screen probe的BRDF重要性采样去guiding;多次bounce的specular需要在世界空间中通过小波存储radiance cache,模拟多次bounce。
如何解决3D纹理过大带来的cache miss问题
纹理压缩:如前面所述,可以使用各种纹理压缩技术(如BCn、ETC或ASTC)来减小纹理的尺寸。这不仅可以减少内存使用,还可以减少缓存未命中的可能性。
Mipmap:Mipmap是一种预计算的纹理金字塔,它包含了原始纹理的多个缩小版本。通过使用Mipmap,GPU可以根据需要选择合适尺寸的纹理,从而减少缓存未命中的可能性。
纹理分块:将大的纹理分割成多个小块,然后只加载和渲染视野中的块。这种技术通常用于处理大型地形或其他大型物体。例如VSM
纹理流式处理:这是一种动态加载和卸载纹理的技术,它可以根据视野和距离来决定哪些纹理需要加载。通过使用纹理流式处理,可以减少内存使用和缓存未命中的可能性。
优化纹理访问模式:尽量使纹理访问模式符合GPU的缓存行为。例如,尽量使纹理的访问模式为连续的,这样可以提高缓存的命中率。
BVH的构建过程?划分节点有哪些手段,各有什么优缺点?
PBRT-E4.3-层次包围体(BVH)(一) - 知乎 (zhihu.com)
- 计算场景中每一个图元的AABB包围盒、质心(一般取包围盒的中心)并存储到数组中。
- 根据不同的划分策略构建树状索引结构。
- 将得到二叉树转化更加紧凑的表示形式(无指针,内存连续)。
中点划分、等量划分、表面积启发式
- 射线和三角形求交,射线与球求交,怎么快速判断?
一文读懂射线与三角形相交算法Moller-Trumbore算法【收藏好文】 - 知乎 (zhihu.com)
射线和三角形求交:重心坐标与射线联立,用克莱姆法则解。可以先判断射线方向是否与平面平行,简化一波
射线与球求交:联立,通过点乘与勾股定理排除一些选项
- 求AABB包围盒与空间中一点的最近点?
1 | |
- 球面分布可以用什么方法表示?
SH球谐函数、小波函数、SG球面高斯、八面体映射,Ambient Cube HL2
球面高斯介绍(Spherical Gaussian) - 知乎 (zhihu.com)
球谐函数介绍(Spherical Harmonics) - 知乎 (zhihu.com)
八面体参数化球面映射方式及实现 - 知乎 (zhihu.com)
说一说PBR的原理?具体的法线分布函数有哪些?
由浅入深学习PBR的原理和实现 - 0向往0 - 博客园 (cnblogs.com)
GAMES202 Physically-Based Rending(PBR) - 王贺的博客 (wangheblog.cn)
以前的渲染是模拟光照的实现,PBR是模拟光照的实际行为。它分别对光源和表面进行了一系列定义。
灯光属性:直接照明、间接照明、直接高光、间接高光、阴影、环境光.....
表面属性:基础色、法线、高光、粗糙度、金属度.....
通过定义灯光来定义灯光的不同属性;通过定义表面来定义不同的BRDF等等。
常用的发现分布函数有beckman、DDX
如果我们要生成成千上万相同的对象,该怎么做?
定义instance(实例),让它们继承于同一个父类mesh。
- 讲一讲渲染方程的物理意义
渲染方程Rendering equation - 知乎 (zhihu.com)
关于渲染方程网上太多资料了.......
- 怎么理解重要性采样?
重要性采样(Importance Sampling) - 知乎 (zhihu.com)(看评论,文章说的好像有问题)
重要性采样可以理解为原本的采样分布不好或者未知,直接在原本的分布上采样或者随机采样得到的方差很大。因此需要重要性采样生成一个新的分布,减小方差。
- 碰撞检测是怎么做的,高速物体碰撞检测出现子弹的隧穿怎么办?
现代游戏物理引擎入门(四)——碰撞检测(下) - 知乎 (zhihu.com)
一种方法是增加检测的次数,在小球这一帧的移动路线上增加多个检测点,总会有位置可以检测到overlap。当然,为了提高检测效率,可以用二分法,这样可以减少不少检测次数。
另外一种方法比起第一种要准确高效的多,简单来说就是把刚体连续移动所覆盖的空间(扫掠体)当作新的形状作overlap检测。还是拿小球举例,其扫掠体正好是一个胶囊体。
- 双重缓冲和垂直同步是否了解?
渲染:垂直同步、双重缓冲、三重缓冲 - 知乎 (zhihu.com)
- 移动端架构是否了解?是否有了解过TBR和TBDR?你怎么理解TBDR中的D?在TBDR上处理半透明物体怎么处理?
渲染架构比较:IMR、TBR & TBDR - 知乎 (zhihu.com)
IMR, TBR, TBDR 还有GPU架构方面的一些理解 - 知乎 (zhihu.com)
- 移动端的on-clip memory知道吗?
(77 封私信 / 59 条消息) 移动端gpu架构中的onchip memory具体是如何运作的? - 知乎 (zhihu.com)
渲染管线中各种test的顺序?
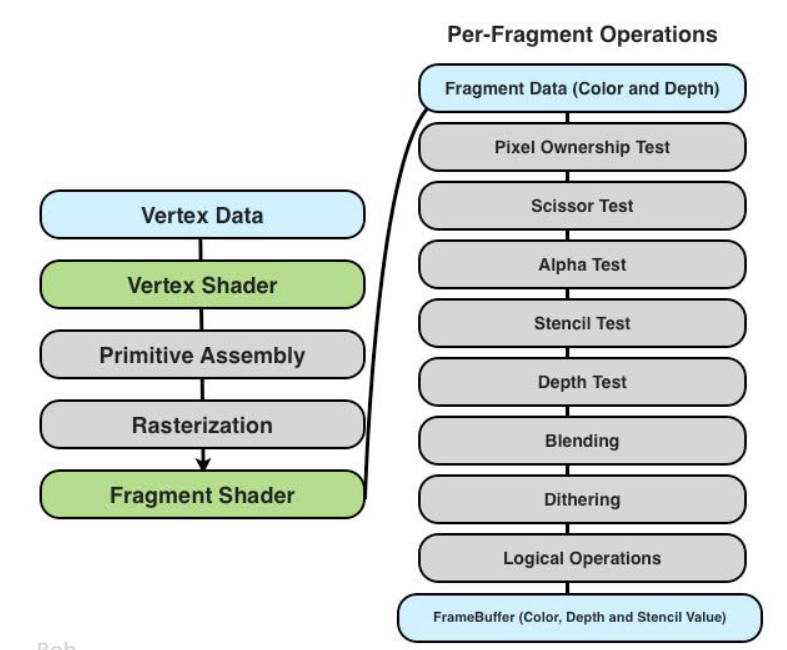
- 裁剪测试:如果一个点在裁剪区域外,我希望它彻底不渲染,也不要对缓冲区造成任何影响,所以优先级最高
- Alpha测试:优先于模板测试,当我们希望用一个不规则的图片进行模板的裁剪的时候,应该使用Alpha测试先过滤掉那些透明的片段,我们只希望剩下的不透明片段来更新模板缓存
- 模板测试:我希望对模板值进行一些更新,所以哪怕我被其它东西挡住,导致这个片段显示不出来,我也要把模板值更新进去
- 深度测试:最后决定这个片段是否渲染
- alpha blend:最终混合
- 纹理压缩有了解吗?移动端的纹理压缩呢?
数值上压缩:法线的八面体压缩、color的YCbCr等
存储的压缩:你所需要了解的几种纹理压缩格式原理 - 知乎 (zhihu.com)
常规性能问题应该如何分析?有哪些优化方向和手段?
金属度(Metallic)有什么用?为什么改变它会影响specular?
Metallic在PBR中 两个因素:
菲涅尔项的F0是通过它插值出来的
1 | |
漫反射系数是通过它计算出来的
1 | |
- GPU Driven了解吗?nanite的遮挡剔除和普通的有什么区别?
理解Nanite(一):遮挡剔除 - 知乎 (zhihu.com)
- 帧同步和状态同步了解吗?
两种同步模式:状态同步和帧同步 - 知乎 (zhihu.com)
- z-fighting怎么处理?
<渲染基础>-3D渲染中的Z-fighting现象 - 知乎 (zhihu.com)
- 欧拉角定义的旋转矩有什么问题,怎么处理?讲一下四元数原理,四元数怎么实现旋转?
彻底搞懂“旋转矩阵/欧拉角/四元数”,让你体会三维旋转之美_欧拉角判断动作_肥肥胖胖是太阳的博客-CSDN博客
- 抗锯齿算法知道哪些?
五分钟搞懂游戏开发中的抗锯齿算法_绿洲守望者的博客-CSDN博客
- MSAA了解多少?8倍的MSAA,缓冲区大小也要8倍吗?MSAA和延迟渲染不能共存只是带宽和显存的问题吗?
延迟渲染与MSAA的那些事 - 知乎 (zhihu.com)
实际上,在2020年的这篇文章中提出了在延迟管线中做MSAA的方法:Multisample anti-aliasing in deferred rendering (eg.org)
图形学论文-Multisample anti-aliasing in deferred rendering - 知乎 (zhihu.com)
深度缓冲区和最终的RT输出要8倍
- TAA存在哪些问题?如何解决拖影?
开销大,需要存储历史帧数据,可能有鬼影。可以通过各种ID去判断是否是同一个物体来消除鬼影
- SSR怎么做的,ray marching是如何进行的?移动端为什么做不了SSR?用什么代替?
SSR就是屏幕空间反射,在屏幕上通过hiz多级mipmap去ray marching。移动端ray marching不了一点,特别费。
Unity URP 移动平台的屏幕空间平面反射(SSPR)趟坑记 - 知乎 (zhihu.com)
- UE为什么要在现有的操作系统内存池上开辟一块自己的内存池?
内存池可以将内存请求抽象出来,使得各种API、各种图形库都可以统一的进行内存的分配与释放,消除平台无关性。
mipmap了解吗?GPU是怎么决定采第几层的mipmap?
AlphaTest和AlphaBlend的区别?效果上看会有什么区别?
有了OpenGL了,为什么还要Vulkan?Vulkan的优势在哪里?
Vulkan是一种较新的跨平台图形和计算API,与OpenGL相比,它提供了更低级别的抽象和更多的控制选项。Vulkan的设计旨在解决一些OpenGL的局限性和性能问题,从而提供更高效、更可扩展的图形渲染。下图分别为OpenGL和Vulkan的整体架构。
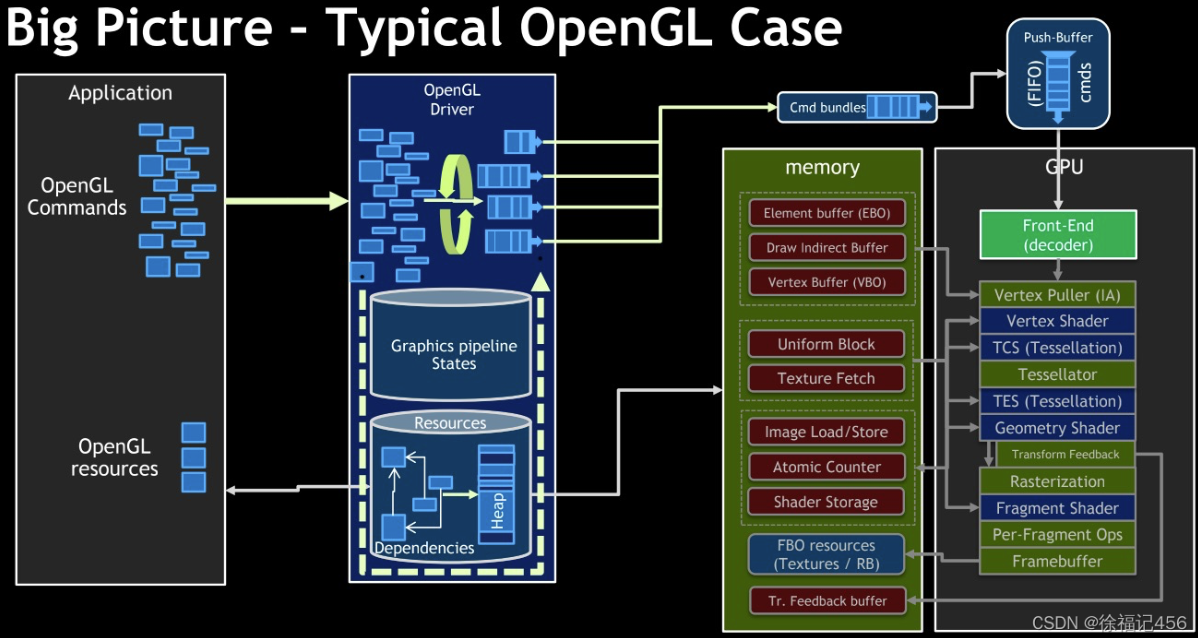
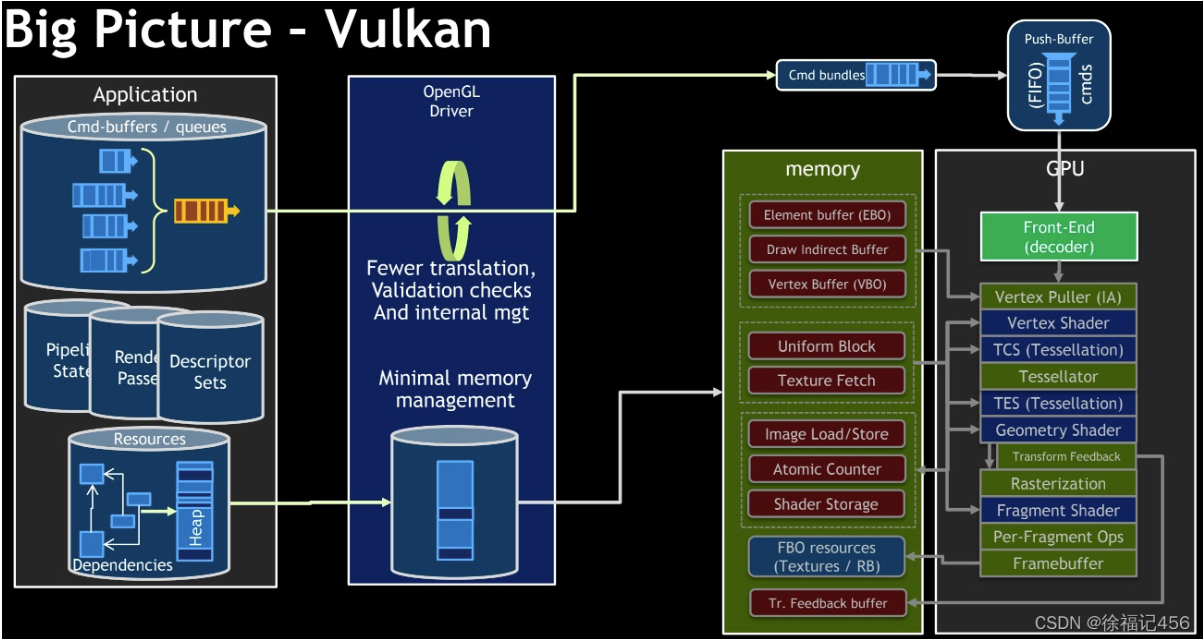
二者的架构都是应用层、驱动层、GPU层。OpenGL命令从应用层经过驱动层,再到GPU层处理;OpenGL资源从应用层经过驱动层(由图像管线状态机管理),再到GPU层的内存。Command-Buffer从应用层经过驱动层,再到GPU层处理。Vulkan资源也是从应用层经过驱动层(由内存管理器管理),再到GPU层的内存。
更低级别的抽象:Vulkan提供了更接近硬件的抽象,允许开发者对渲染管线和资源管理有更多的控制。这使得Vulkan可以实现更高的性能和更细粒度的优化。相比之下,OpenGL是一个高级API,它提供了许多内置功能和默认设置,使得开发者能够更轻松地实现图形渲染,但牺牲了一定的性能和控制能力。OpenGL的管线是写死的,通过类似于状态机的机制实现对底层的完全封装,编程者只需要像填空一样设置好输入即可;Vulkan将底层可编辑部分完全交给编程者,由内存管理器处理,效率更高但也更复杂。
显式内存和资源管理:Vulkan允许开发者显式地管理GPU内存和资源,如缓冲区、纹理、渲染目标等。这可以提高内存利用率,减少内存碎片,从而提高渲染性能。相比之下,OpenGL的内存和资源管理是隐式的,由驱动程序和硬件自动处理,这可能导致内存浪费和性能瓶颈。
多线程友好:Vulkan天然支持多线程渲染,允许在多个线程中同时执行命令缓冲区的构建和提交。OpenGL在资源提交到renderpass之前就为资源定义好了执行角色(线程),Vulkan在renderpass时才为资源分配线程,这是将renderpass重组为多个subpass来实现的。可以做到运行时动态多线程,支持一些高级的图形API特性,例如RDG等等。这可以充分利用现代多核CPU的性能,提高渲染效率。相比之下,OpenGL的多线程支持较弱,大多数OpenGL调用需要在单一线程中执行,这可能导致性能瓶颈。
更好的错误检测和调试支持:Vulkan提供了一套可选的、分层的验证和调试机制,允许开发者在开发过程中检测错误和性能问题。这可以帮助开发者更快地找到和修复问题,提高开发效率。相比之下,OpenGL的错误检测和调试支持较弱,通常需要使用扩展或第三方工具来实现。
更好的跨平台支持:Vulkan是一个跨平台API,支持多种操作系统和硬件平台,如Windows、Linux、Android、macOS等。Vulkan还支持SPIR-V中间表示。SPIR-V全称Standard, Portable Intermediate Representation - V,是一种用于GPU通用计算的标准化中间语言。允许开发者在不同平台上使用相同的着色器代码。相比之下,OpenGL在不同平台上可能存在兼容性和性能差异,需要使用扩展或特定的API版本来实现跨平台支持。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!