GDC2023 Two Level Radiance Caching 简析
本文最后更新于:5 个月前

1 Brief Introduction
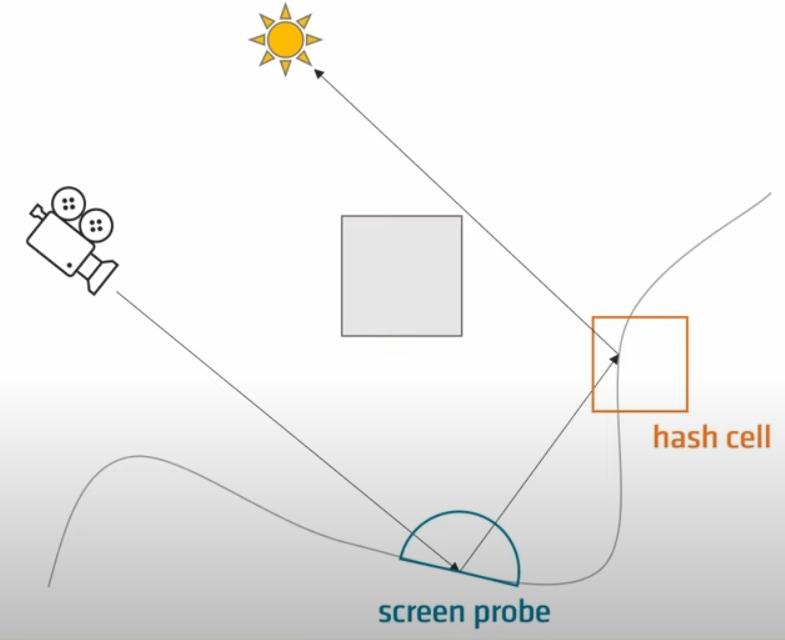
采用二级radiance cache,第一级是屏幕空间的probe,也就是UE5的finalgather,缓存整个半球的入射radiance,第二级是世界空间的hash cell,缓存八面体中给定方向的radiance。在管线中使用V-Buffer+G-Buffer结合的方式(主要是V-Buffer),ray trace方式采用rayquery,保存hit ray的信息。从hit ray中拿到instance ID,继而从meshbuffer等读取相关数据,包括world position、normal、material、emissive等。
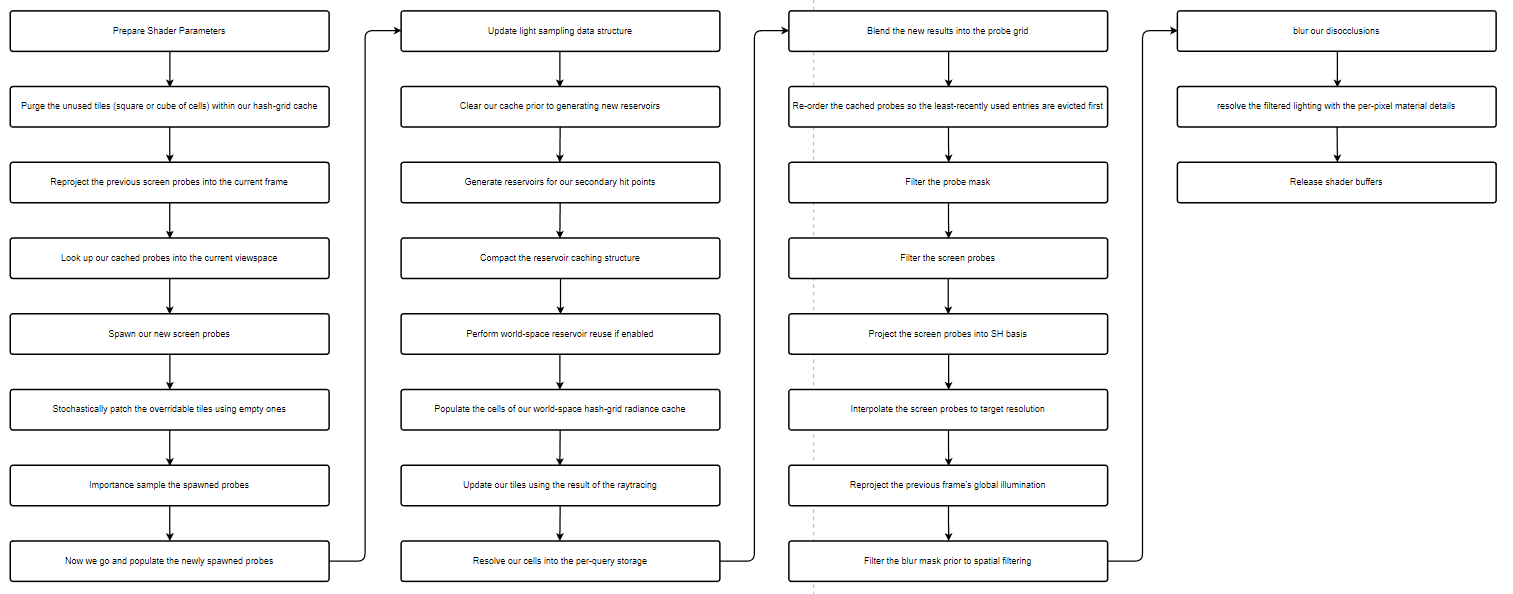
不考虑采样等操作,每一帧对于GI的基本操作流程为:
- 在屏幕空间中生成新的screen probe
- screen probe发射光线去hit到某点生成新的hash cell
- hash cell收集直接光照数据
- screen probe 获取 hash cell的光照,作为indirect保存下来
- 混合screen probe,生成最终的lighting texture
2 Final Gather Screen Probe
每个probe通过八面体映射存储irradiance,最后遍历像素,每个像素插值平均周围四个probe。这种基于屏幕空间放置probe的方式很高效,每个probe都是有用的,并且可以通过深度等获得几何信息,避免漏光。
2.1 Probe Temporal
2.1.1 Reprojection Placement

将屏幕分为8*8的tile,每个tile里放置一个probe,采用8为单位是因为更好的内存对齐,并且屏幕分辨率通常也都为8的倍数。在最开始的光栅化追踪中,需要相机对每个像素投射一条primary ray,这样很费,因此每帧更新1/4,4帧之后可得到完整结果。
分帧是一种非常重要的加速手段。但是Temporal是每帧完全进行的。
由于在Finalgather中放置probe的基本单位是8*8的tile,因此Probe Temporal Reprojection(探针时域重投影)也是以tile为单位的。我们通常以GBuffer的分辨率作为Probe Temporal Reprojection的分辨率,但是实际上也可以以低分辨率进行,特别是在开启了FSR的情况下。对于某一个tile而言,整个重投影流程分为三步:
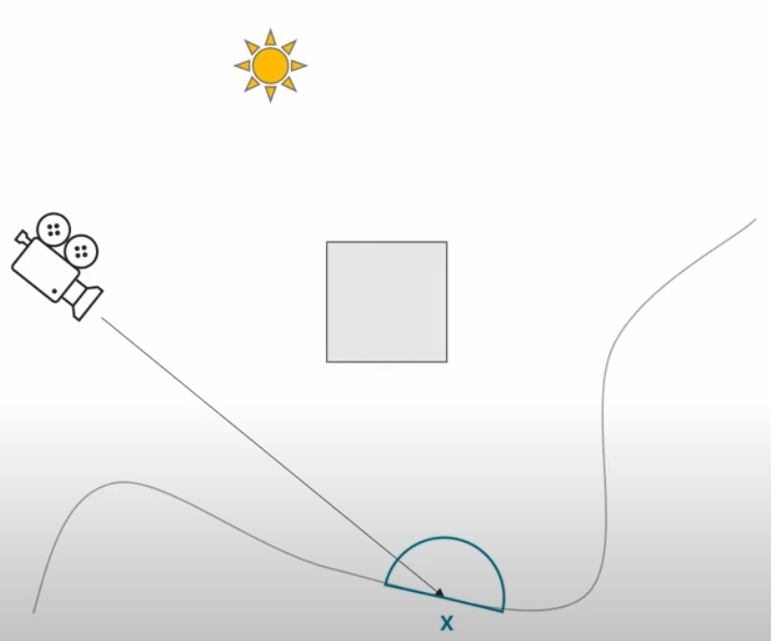
- 遍历每个pixel,通过motion vector等变找到上一帧的位置,查找附近最近的probe(上文我们在每个tile中只放置了一个probe,所以实际上这些pixel找到的都是这个probe)。如果重投影失败,我们做一个标记(上图的x)。若重投影成功,我们通过GBuffer信息做一个类似于SVGF的评估,得到一个reprojection score用来量化评估结果。
- 我们定义一个32位的GroupShared本地共享变量,用来存储每个pixel的评估结果。为了方便比较,在高16位存储reprojection score,低16位存储这个像素的位置。在遍历每个像素时,都将得到的新结果与GroupShared中的变量进行比较,采用LDS(Local Data Share)中的InterlockedMin()原子操作取最小值并更新(这里默认评估的reprojection score越小越合适)。
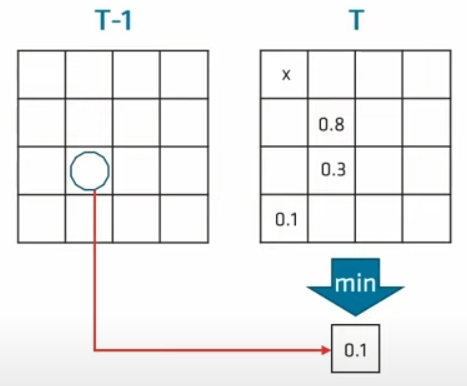
- 将上一帧的probe放置在本帧对应tile中评估效果最好的pixel上,找不到对应probe的话也放置一个标记。
2.1.2 Fix Holes
由于遮挡和视角移动等因素,我们会在上一个步骤中标记出很多无法重投影成功的tile,我们称之为孔洞(Hole),这些hole已经被标记。需要采用适当的方法填补这些hole,总体的思路就是移动附近新生成的probe去进行填补。
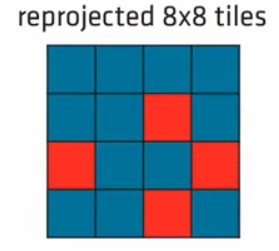
对于这些孔洞,我们以8*8为一个更大的Grid进行处理。如上图,蓝色为重投影成功的tile,红色为失败的。
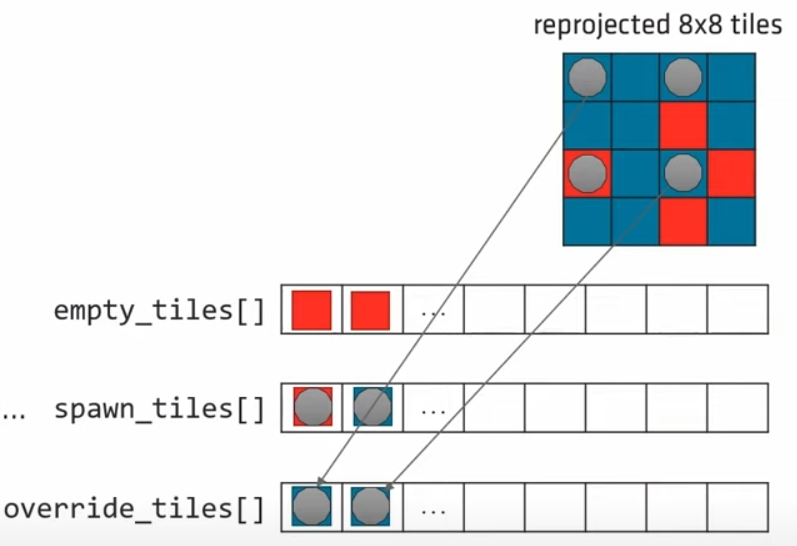
在probe生成时我们提到过采用分帧策略,每帧生成1/4。对应于上图,即我们在每2*2的tiles内每帧生成一个,图示在左上角生成(灰色圆点)。对于每个Grid,我们维护三个数组:
empty_tiles[]:记录当前Grid中所有Hole的位置
spawn_tiles[]:记录当前Grid中新生成的probe的位置
override_tiles[]:当前Grid中新生成的probe中,记录已经重投影成功的,但是又在上面生成了新的probe的tile的位置
然后随机地在override_tiles[]中选取probe,将其填充至empty_tiles[]中,代码示例如下:
1 | |
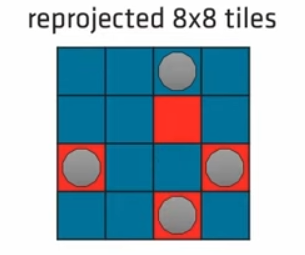
上图为填充后的结果。注意到,并不是有足够的override_tiles就会将hole全填上,因为我们要保留一些新生成的probe引入新的Temporal信息。例如2.1.1的重投影过程中,如果我们完全依赖上一帧的probe,会导致probe可能只在特定的某几个texel上生成,这种情况在深度差异很大时特别明显。
2.1.3 Hemisphere Reconstruction and Ray Guiding
每个probe都在半球方向累积并存储radiance。如果我们新生成了一个probe,我们可以通过复用周围重投影成功的probe的数据去直接构建半球光照,不同重新去trace ray了。
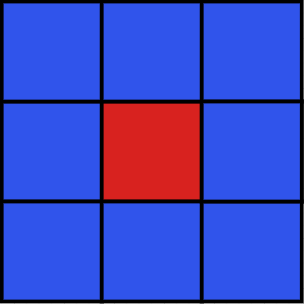
如上图,红色区域是本帧新生成的probe的位置,我们复用周围3*3的重投影probe。由于半球光照是具有方向属性的。因此在遍历周围八个probe时,我们也需要将direction重投影到新生成的位置(就是计算二者之间位置的偏移)。由于我们采用八面体存储radiance,因此我们同样采用4个LDS的InterlockedAdd()原子操作,计算完周围所有的radiance之后进行归一化,然后写入新生成的probe的八面体数据中。
为什么要如此精确的重构半球radiance呢?因为我们可以通过它结合CDF(Cumulative Distribution Function)进行ray guiding。报告里并没有提及具体用到了哪种方法,这里简单介绍其中一种:
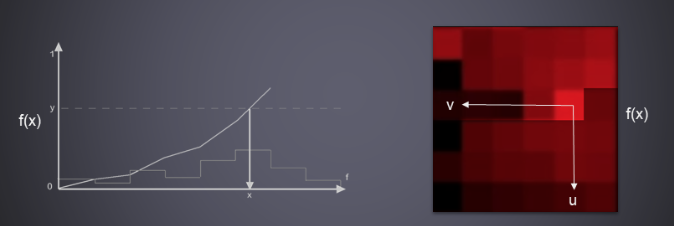
我们将半球方向上的Luminance(此处可以是Luminance,也可以是乘以abedo之后的radiance)以2D平面展开成一个6*6的cell,f(x)为该点的Luminance。由于写入了rgb的r通道,看起来是红色的,如右图所示。左图的x轴为右图的横向线性分布,y轴为f(x)的值。当我们需要随机采样一个方向时,可以在(0,1)之间随机选取一个值,将它与这个cell中f(x)的累计值相乘,结果记为y。 \[ y=\operatorname{rnd}(0,1)* \operatorname{sum}(f) \] 从原点开始,依次将每个pixel内的f(x)累加,直到某一点使得累加的值大于等于y。将该点的uv坐标映射回半球,就可以得到该点的ray方向;同时该点的f(x)即为它的PDF未归一化结果。
2.2 Fix Final Holes
到这里,我们填补了重投影产生的大部分holes,并合理地写入了光照数据。但是如2.1.2节最后的图所示,还是有一些holes没有被填上。如果不填的话会有能量损失。这时有两种策略:
- 在该点生成新的probe,然后trace rays
- 直接拿历史帧的数据填补
- 在该点生成新的probe,然后傻瓜式采用LDS平均周围已有的probe

策略1会重新进行大量ray trace,策略2会造成经典的Temporal鬼影问题。为了提升性能且获得快速收敛效果,AMD最终选用的第三种策略,对于绝大部分简单的场景来说效果还不错。
2.3 Screen Tile Radiance Blending
2.3.1 Temporal Filtering
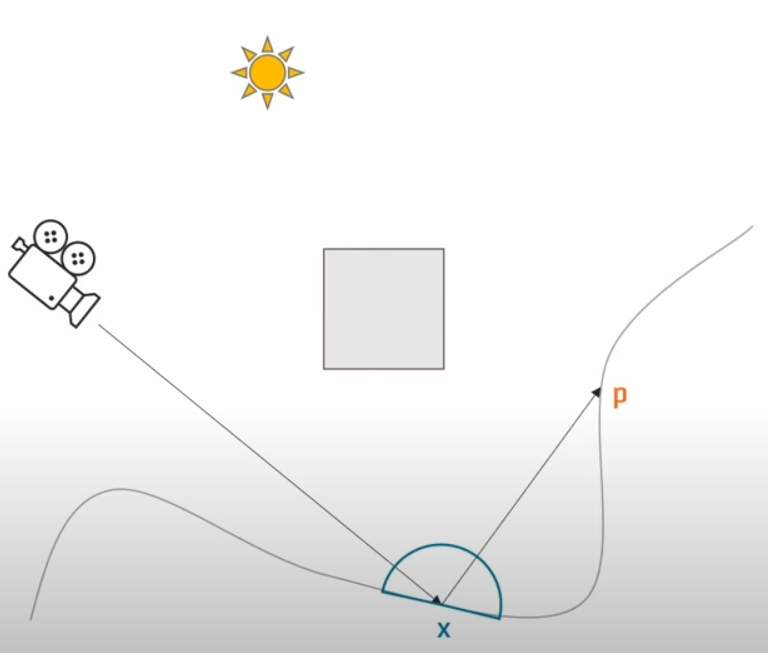
上文中我们将屏幕空间分为8*8的tile,在每个tile内生成一个final gather probe。接下来我们在每个tile内通过2D抖动选择一个pixel,然后将其反向投影到世界空间,作为我们ray trace的起点。假设某一条光线击中了点P,从2nd radiance level中获得了点P的radiance,然后需要将这个radiance和已有的历史数据进行混合。
由于一个tile投影到世界空间中的面积可能会很大,所以直接进行线性混合,或者采用滑动平均进行计算的话,会造成过渡模糊。我们动态调整当前和历史的混合参数α: \[ C_i=\alpha C_i+(1-\alpha) C_{i-1} \] 使得较暗的样本的α系数更大,具有更高的权重。 注意,这样做会导致画面整体变暗,但是当开启ray guiding时,通过调高guiding的精度,在大多数场景下可以缓解变暗的问题。
2.3.2 Probe Masking
我们使用多级的probe mask texture进行快速的邻接查找。

首先,我们在屏幕空间中每8*8的tile内存储probe的位置,无probe的话就放置一个失效标记(图中红色部分),从这个图开始进行多级mip创建。

第0级mip只是将原texture中失效部分提取出来。

我们从第0级mip开始,每2*2个pixel合并为一个新tile作为下一级的新pixel来降低分辨率。新pixel内的值为四个原pixel中顺序第一个不为失效标记的值,若全失效则放置失效标记。

第二级mip可以看出,已经没有孔洞了,因此结束创建流程。
查询时,从初始mask texture mip 0开始查询。例如我要找右侧最近的probe,先在mip 0内向右查询一个pixel,若是hole,则返回原像素,找到在mip 1上对应位置,在mip 1上向右查询……这种mip mask的方式在空间filter和插值计算中有广泛应用。
2.3.3 Probe Filtering
设置在7*7的范围内进行filter,且在计算权重中额外考虑了到平面的距离(一种双边权重)来避免漏光。
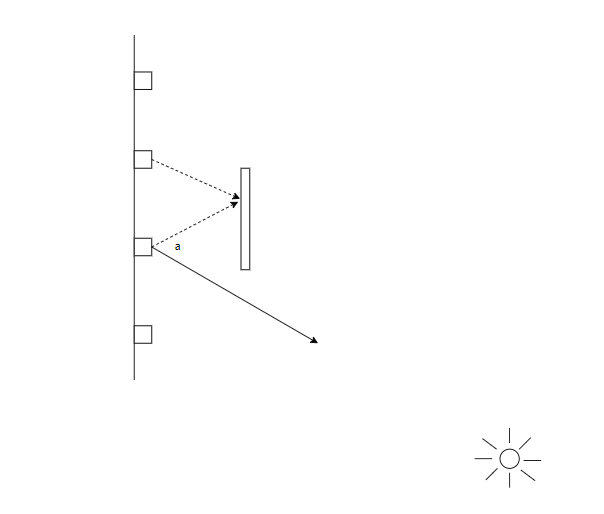
同时,也引入了角度filter来避免漏光。这个地方视频里说的很草率,2021的报告里Radiance Caching for Real-Time Global Illumination - YouTube图画的也很含糊,我这里就详细画了一张图来解释。如上图,左边墙面上有四个final gather probe,中间是一个遮挡物,右边远处有一个强光源。正常来说第二个probe是被遮挡的。但是在filter的过程中,如果直接找周围一定范围内进行平均的话,会导致漏光。例如上图第二个probe与临近的第三个probe直接平均就是错误的。因此我们复用原probe某个方向的ray的hit position。与需要参与filter的probe的位置进行连线,比较这个连线与原ray direction的夹角大小。夹角和hit distance共同计算一个新的权重,夹角与权重成反比,hit distance与权重成正比,过远的话权重直接为1。
2.3.4 Persistent LRU Side Cache
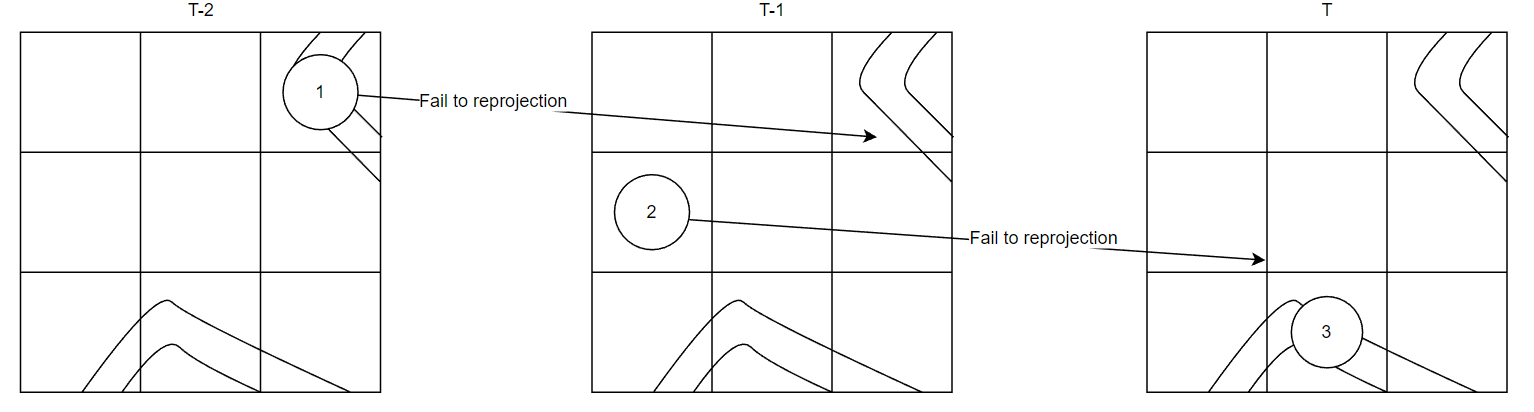
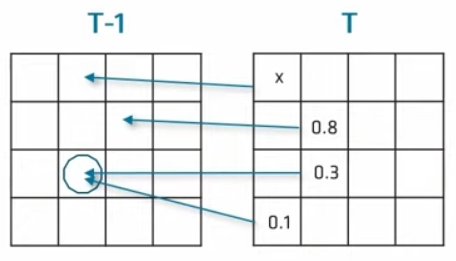
当在某一个tile中新生成了一个probe时,若可以temporal找到上一帧的probe,可以直接复用这个probe的光照信息重建半球。上图为连续三帧某一个tile内的reprojection情况,左上角和下方是两个几何和位置信息近似的薄平面。
在T-2帧中,在左上角薄平面上生成了一个probe,标记为一号,在第T-1帧中生成的二号probe发现虽然一号重投影成功了,但是与一号几何信息相差太大,无法用来重构半球光照。在T帧中生成的三号probe发现又无法重用二号。实际上,三号是完全可以重用一号的信息的,但是由于太过久远,一号已经寄了,因此需要一定的操作手段保证这种“隔帧复用”。
我们采用LRU(Least recently used)算法来实现。每一个tile维护一个LRU队列,当某一个probe重用失败时,就会把它放入队列中。即每个放置到队列中的probe需要满足两个条件:
- motion vector的映射是成功的
- 但是本帧在另外的pixel上生成了新的probe,是高优先级的,且它还不能为新probe重构光照
每当生成一个新的probe,若重用上一帧失败,还会继续检测是否可以重用队列中的probe,若重用成功,把重用的对象移动至队头。

如上图,为一个有很严重的深度和几何不连续性的场景,在边缘处会有很多probe重新生成并累积光照,产生fireflies(萤火虫)现象。

上图是每个tile里LRU的可视化场景,可以观察到更新频率非常频繁,这是由于LRU队列中一直在重新排序,并且当我们在LRU队列中重用成功之后,我们也会在本帧更新光照,保证新生成的probe的光照数据一直都是最新的。

上图为LRU机制处理之后的结果,可以看到基本消除了fireflies现象。
3 The 2nd level WorldSpace Radiance Cache
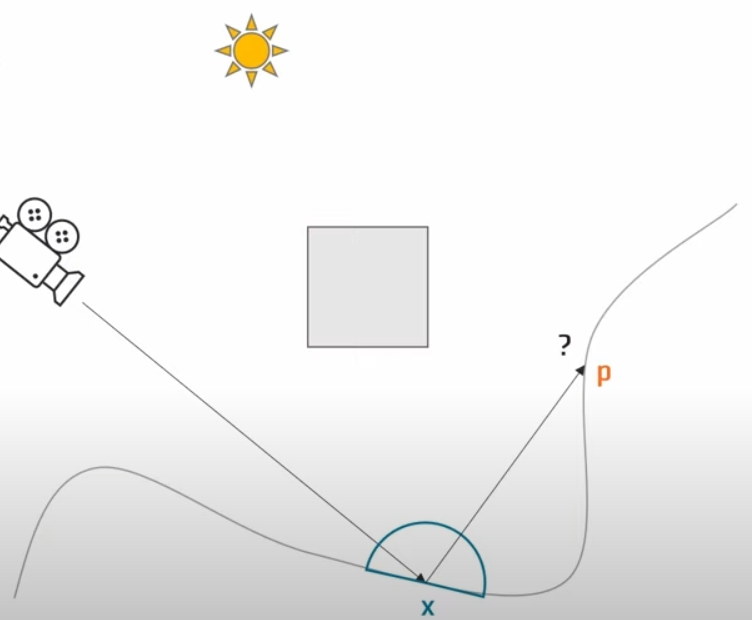
如图,我们解释完了屏幕空间中的radiance计算方式,下面我们来讲解如何从点P获取indirect lighting。
3.1 Temporal Radiance FeedBack
解释起来非常简单:我们将点P投影回屏幕,然后通过motion vector计算上一帧temporal的位置,比较深度和法线,如果上一帧可见,那么直接复用历史数据即可。这样做会减少大量的开销,并且无意中模拟了muti-bounce的结果。
3.2 Spatial Hash Grid Radiance Caching
3.2.1 Introduction
对于不可见的world position,我们采用空间hash的方式动态生成和销毁散列radiance网格。
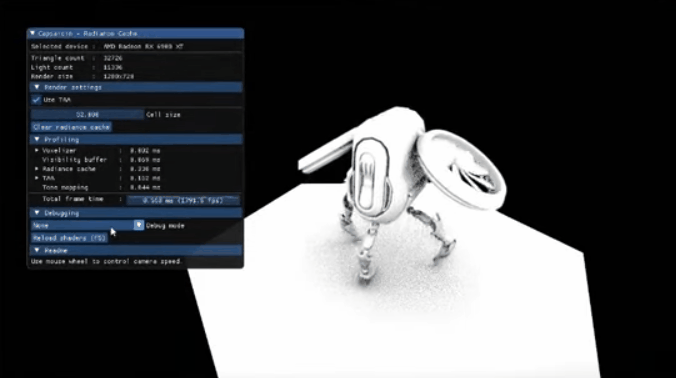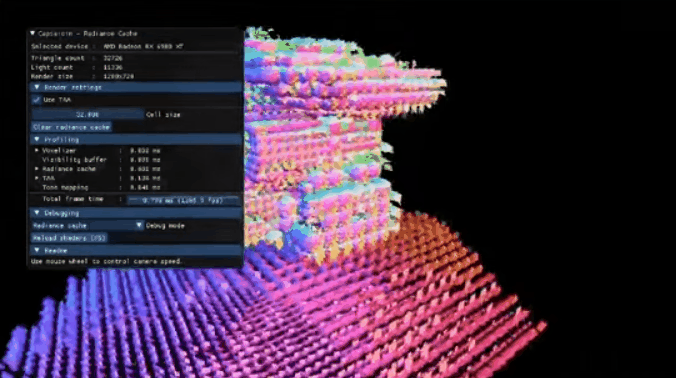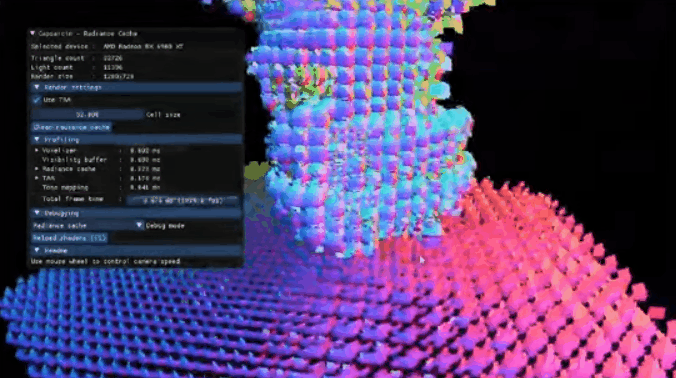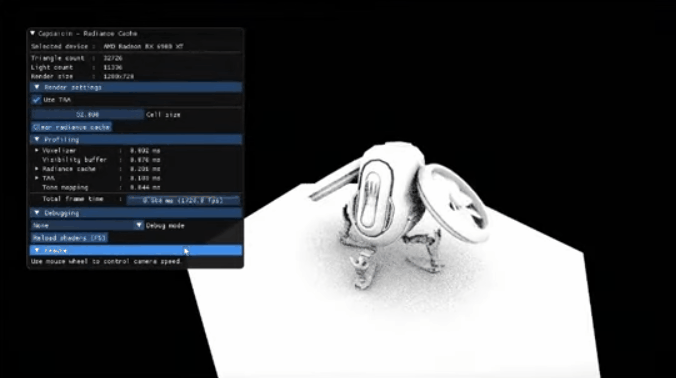
上图是一个动态飞行器的网格可视化。我们可以发现几个特点:
- 无需预先准备任何数据,所有的数据都是根据几何结构adaptive动态生成的
- 只有生成的时候才会动态分配内存
- 具有回收机制
具体流程是:我们直接在世界空间内做tracing,在hitposition检查网格数据,若未生成过网格则新生成,然后放置一个回收周期;若已生成,则将回收周期调整至最大。每帧结束后回收那些需要回收的网格,可以直接从内存中删掉或者做其它操作,达到了动态回收的效果。
3.2.2 Adaptive Filtering Heuristics

如果以相同的精度考虑整个场景,越远的距离我们能看到的物体越多,需要纳入考虑的细节也越多。但是实际上远处的物体精度再高,受到屏幕分辨率的限制,投影到屏幕上也就是一小部分的像素块。因此对于世界空间的hash网格使用了Radiance LOD(Level Of Details)来自适应场景尺寸。如上图,距离越远的地方精度越低,网格尺寸越大。
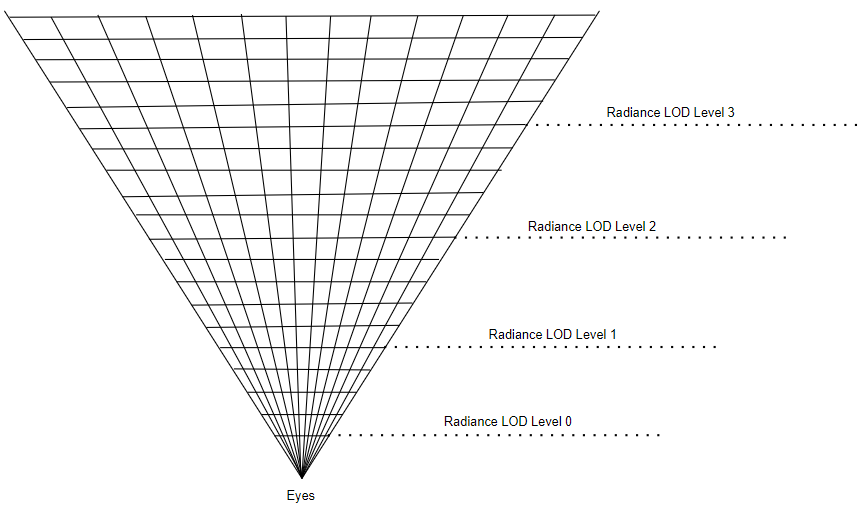
因此我们要保证一个原则:近处的网格和在远处的网格投影到屏幕上所覆盖的像素区域应该大致相同。反过来想,我们把屏幕上某一块像素区域向外做视椎体投影,投影到各个距离的实际面积就应该是它在该位置的实际网格尺寸,因此我们以视椎体为依据建立多级LOD,如上图。这是一种自适应的LOD算法,同时也可以应用到finalgather在世界空间中的检测范围判定。为了增加稳定性,远处的probe可以有更大范围的radiance重用,当然这样会引起更多的偏差。
3.2.3 Spatial Hash Grid
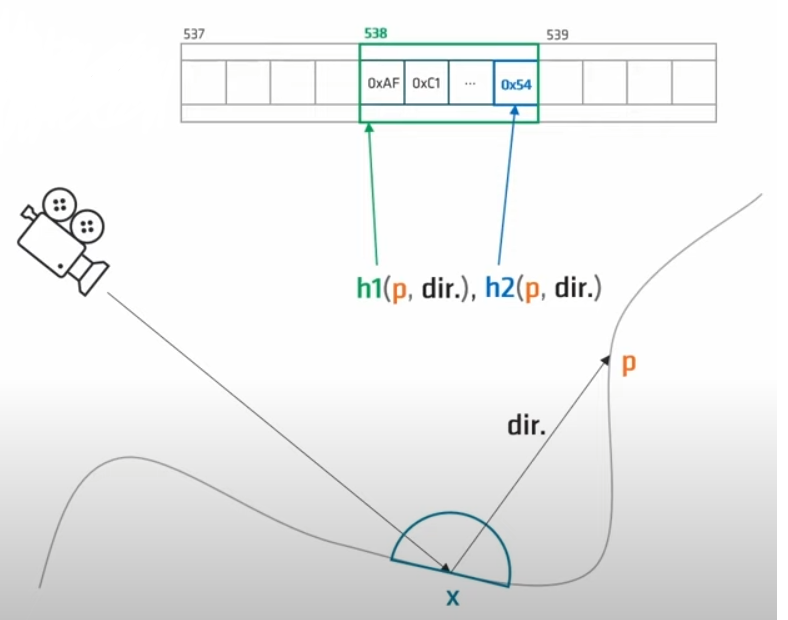
本流程是新生成的probe或者已经存在的probe会每帧发射出一定数量的光线,计算direction和hit_position,将击中的网格写入hash array中。
首先介绍几个原子操作函数:
1 | |
我们现在有一条ray和hit position如何在hash中查询到对应的保存位置,然后进行数据查询或者保存呢?详细流程解释如下:
- 输入与计算hash种子:
1 | |
其中,对于hit_position和direction的转换如下:
1 | |
hit_position只是计算出它的体素化网格坐标;而direction则是根据三个分量的正负(所处的象限)映射到一个8个值的map,可以理解为八面体。direction的映射如下:
1 | |
这样,就把任意的输入转换为hit的网格坐标+八面体八个方向其中之一,作为种子进行最终的hash。
- hash的计算与索引查询:
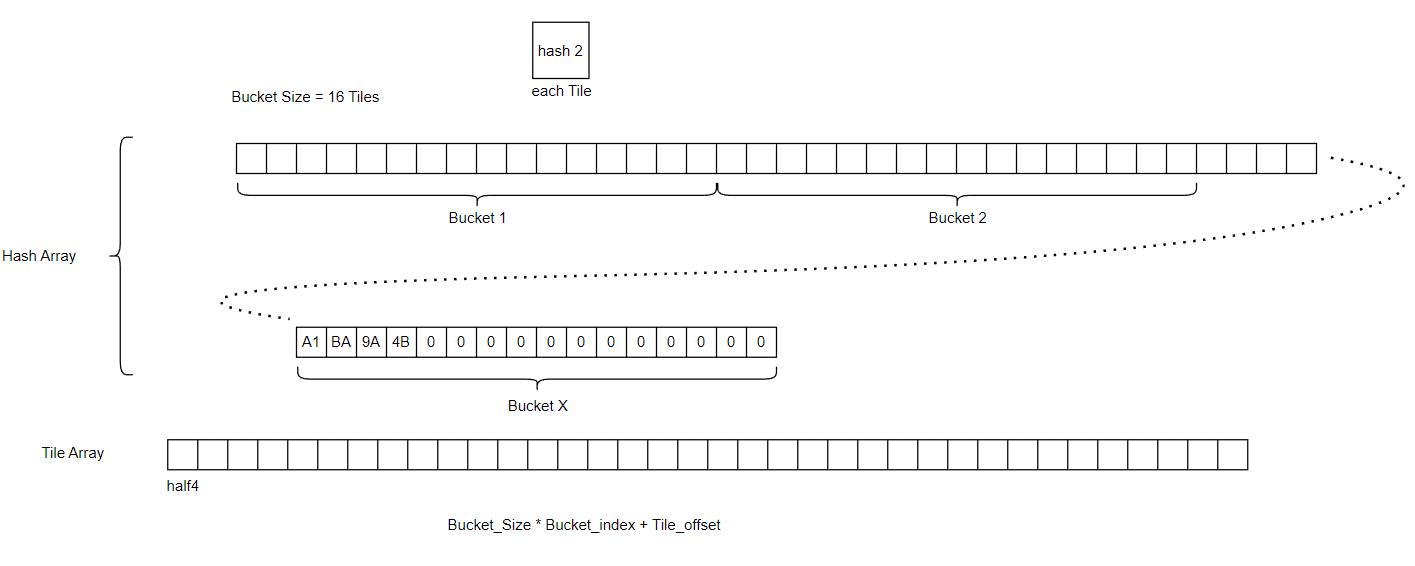
我们通过两种不同的方式对于每个hit的网格坐标+八面体八个方向其中之一计算出两个hash值。第一个值作为Bucket的索引,第二个值作为自己的标识符写入tile中。
当我们有一个新的输入时,具体的计算流程为:
计算hash种子
根据Bucket索引查找到对应的Bucket
在Bucket中使用InterlockedCompareExchange()函数线性遍历每个tile,当某个tile标识符为0时将自己的标识符写入,然后设置new_tile标记,保存Tile_offset等信息,返回Tile_offset;当查到相同的标识符时,返回Tile_offset位置;bucket越界时返回invalid。
- Tile的2D展开
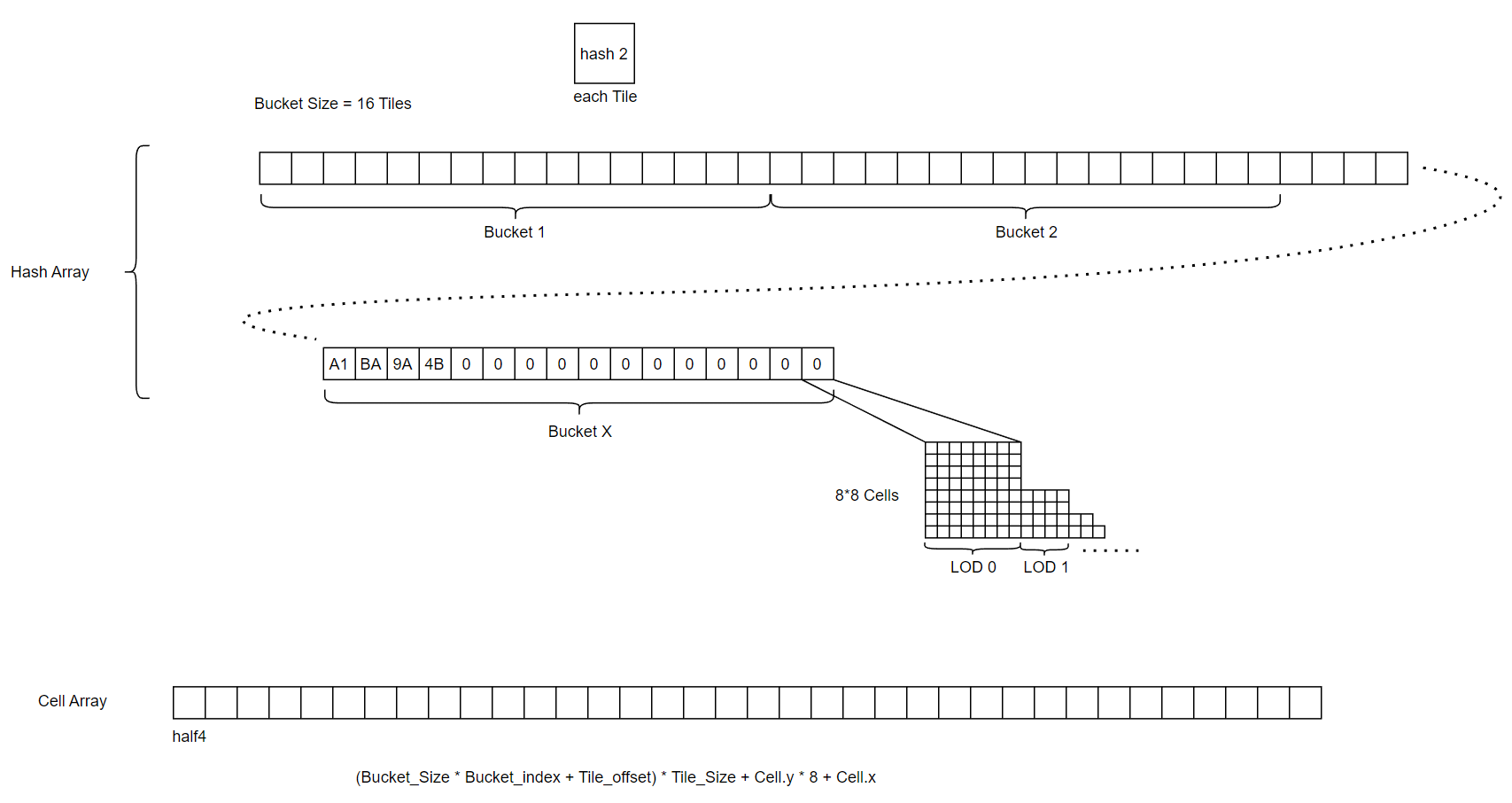
到这里,已经完成了基本的hash。但是我们对于每个网格的八面体每个面都留了一个hash位置,这显然是不够的,这样对于每个面只能存一份数据。因此我们把tile展开为8*8的2D网格,根据direction和hit_position计算2D网格的UV坐标。最终形态的hash如上图所示。
这里的坐标转换十分复杂难懂,首先求得hit_position在世界空间某一个网格(体素化网格)内的局部坐标,然后按照direction较小的两个分量去取局部坐标对应的分量作为2D网格的UV坐标。
上述中的hash过程可知,每个tile实际上是一个体素化网格在八面体其中一个面的方向上的数据。先不考虑方向,我们把体素化格子再次细分为8*8*8的小格子,按照上面的要求把每个tile分为8*8的Cells,实际上就是解决如何把体素化格子的8*8*8映射到tile的8*8的Cells的问题。我们首先计算hit_posotion在8*8*8的网格内的坐标,但是得到的也是个三维向量,如何映射到二维呢?
三维到二维其实是做投影,那么我们引入direction进行控制,舍弃direction三个分量中绝对值最大的分量,取另外两个分量对应的hit_position的局部坐标。例如hit_position = (1,2,3),direction = (-8,-6,3),那么取hit_position 的yz坐标(2,3)作为tile的2D UV,当然我举的例子是没有归一化的。
引入direction之后,direction引入了三种情况,所以最终的映射实际上是8*8*8*3映射到tile的8*8的Cells的问题。
下面我对坐标进行降维,以第一象限为例做了一个解释:
- 3D 8*8*8的网格 ——> 2D 8*8的平面
- 3D hit_position ——> 2D 平面坐标
- 3D direction ——> 2D 平面向量
- tile 的2D展开 ——> 一维线段
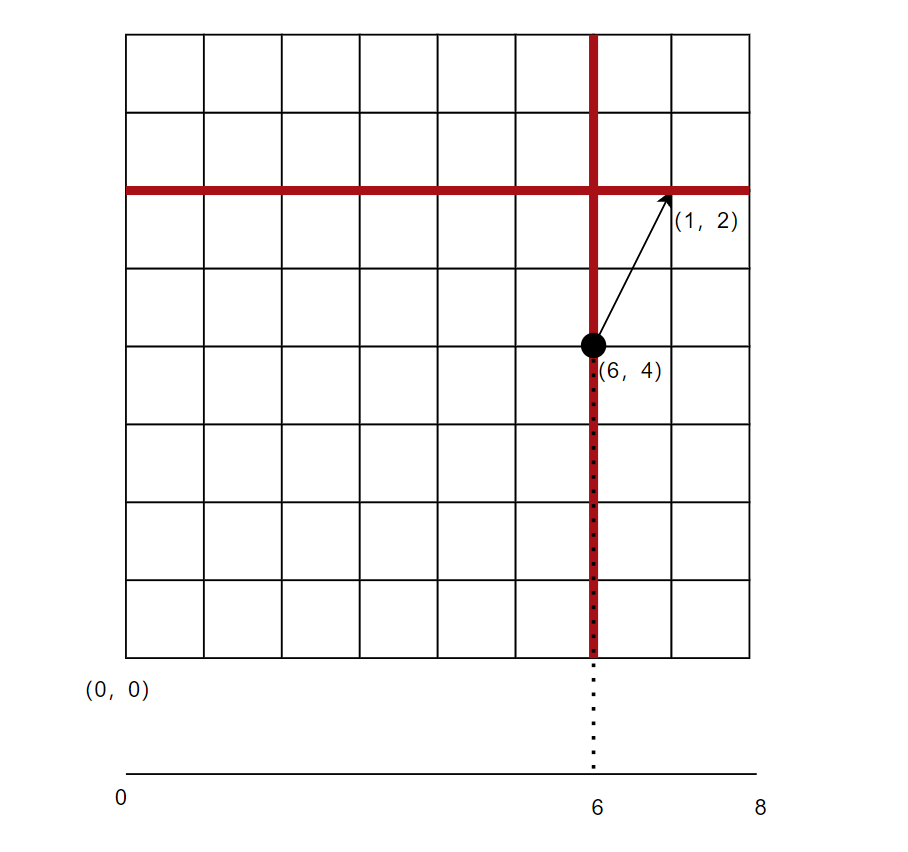
hit_position = (6,4),direction = (1,2),我们取x坐标,最终在一维线段上的投影就是6。我们注意到,上图中两个红线的点,垂直红线的所有点在direction.y > direction.x 时,投影结果是一样的,这就是降维投影的过程。水平投影在direction.x > direction.y时投影也是一样的。本例中解决了8*8*2映射到tile的8的Cells的问题,举一反三到上文的三维空间也是一样的。
- 数据保存与光照注入
每当发现新的Cell,我们会在一个Cell_number计数器中申请一个新的index,以index为索引保存ray的相关信息、V-buffer的索引、Cell_Array的位置等。
1 | |
3.3 Light Leaking
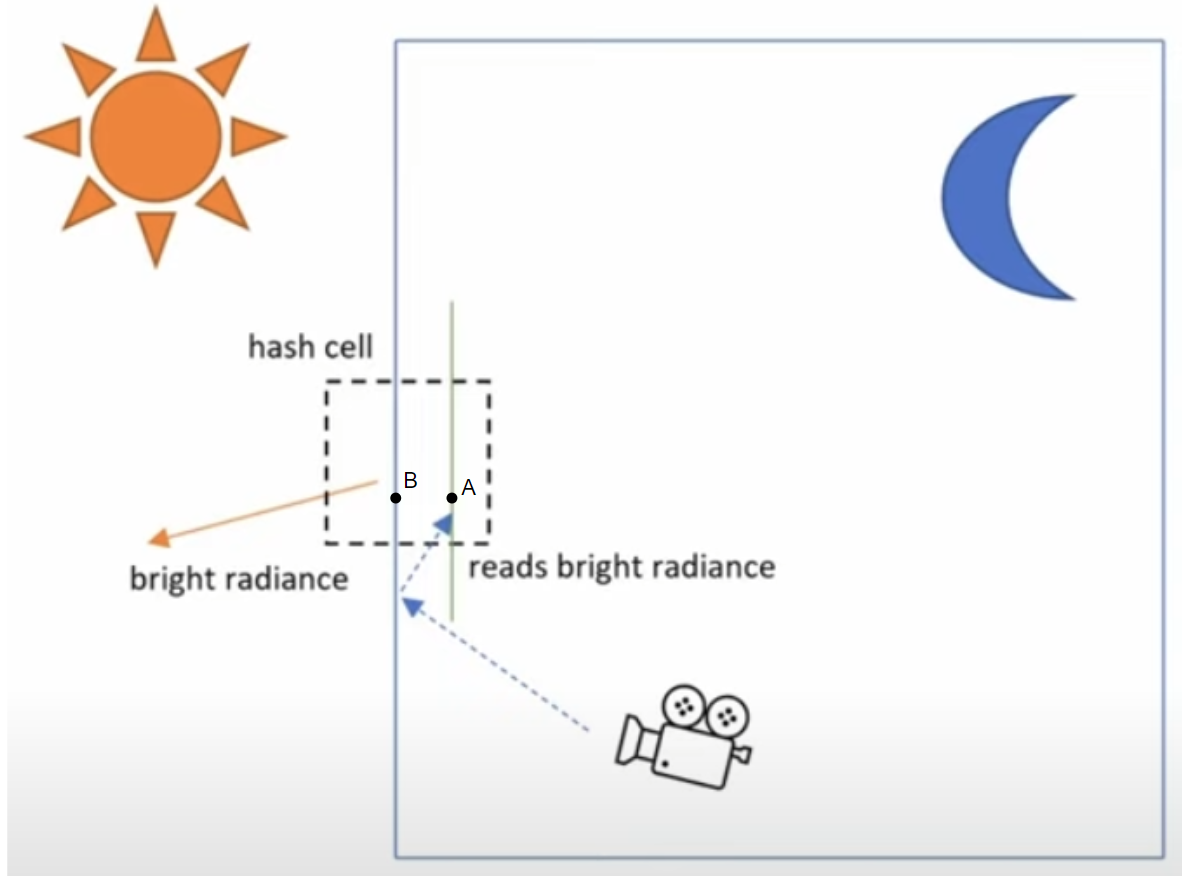
我们在每个体素化网格cell内是通过position和direction计算索引的,对position的floor操作可能会导致漏光。如上图,墙内的点A与墙外的点B同处一个体素化cell中,它们的world position是如此之近以至于在hash的过程中取floor操作得到的局部坐标是相同的。在收集光照的过程中,在橘红色的方向有一个很亮的光源,radiance信息被写入到这个方向内。在camera获取光照的过程中,有一些indirect lighting击中点A,它的坐标和点B差不多,当入射方向也和橘红色方向的八面体位置一样时,墙内的点A与墙外的点B在hash中被映射到同一位置,造成漏光。

墙边的漏光。
解决方法是:这种漏光存在于hit_distance < Cell Size 时,我们将条件引入hash计算:
1 | |
这样,墙内的点A与墙外的点B会被映射到不同的hash索引中,解决了漏光。

4 Light Sampling
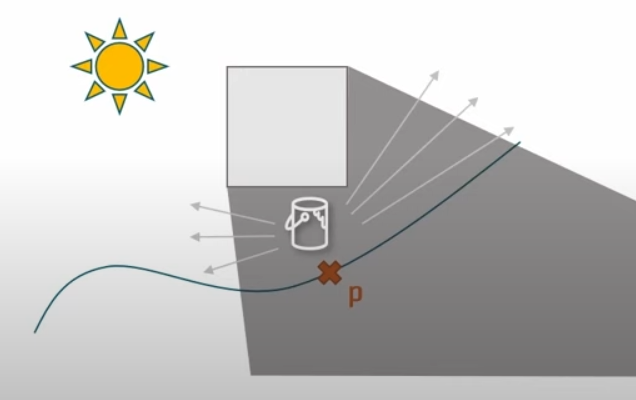
对于 2nd radiance cache的点P而言,我们使用基于ray query的shadow ray,结合世界空间的ReSTIR蓄水池进行sampling。
首先,ReSTIR希望蓄水池中的样本从开始就是稳定的,因此我们在世界空间中按照上文划分的网格进行了一波light culling,判断AABB将对本cell有影响的光源写入本cell的列表中。
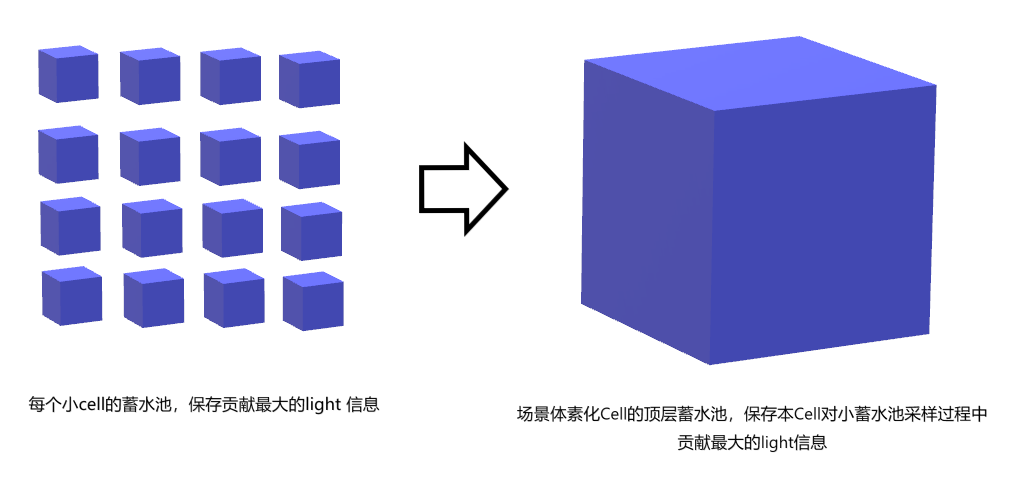
如上图,我们通过之前存储的V-buffer数据列表遍历3.2.3中每个体素网格内生成的小cell,通过instanceID可以精确定位到mesh,拿到world position、normal、material等数据。从每个cell出发,在本大cell光源列表中随机选取8个进行shadow ray,评估每个光源的贡献,将影响最大的光源信息和PDF存储下来,作为蓄水池的样本;然后在整个大cell的范围内从样本中随机抽取一部分进行混合,选取出最有影响的光源和PDF,作为本大cell的顶层蓄水池结果。
这样在每个小cell每帧进行direct lighting评估时只需要向顶层蓄水池保存的一个light index发射一条shadow ray即可,达到了每个cell只投射一条shadow ray的效果。结果用四次InterlockedAdd()函数写到cell_index对应的位置中。


5 Irradiance Interpolation
5.1 Interpolation

到目前为止,我们可以通过我们一整套流程,得到每个screen probe里面的irradiance,如上图所示。但是screen probe并不是填充于每个像素的,而是分8*8的tile生成的。因此要获得像素级别的结果的话,需要对每个像素进行差值。差值过程很简单,对每个像素进行着色时,检查周围四个probe的颜色进行混合,通过简单的深度判断避免漏光,用蓝噪声来隐藏一些artefact。

最终的结果。

但是这种简单粗暴的方式会带来一个问题。如果当前pixel检测的四周四个probe全部失效,它就不会获得任何数据。这时我们令它强制混合四个probe的颜色,但是在a通道上设置一个特殊的标记值。在temporal重投影过程中检测此标记,若符合则该像素不可用。结合probe的抖动,可以逐渐优化这个问题,如上图。
5.2 Denoising Pipeline
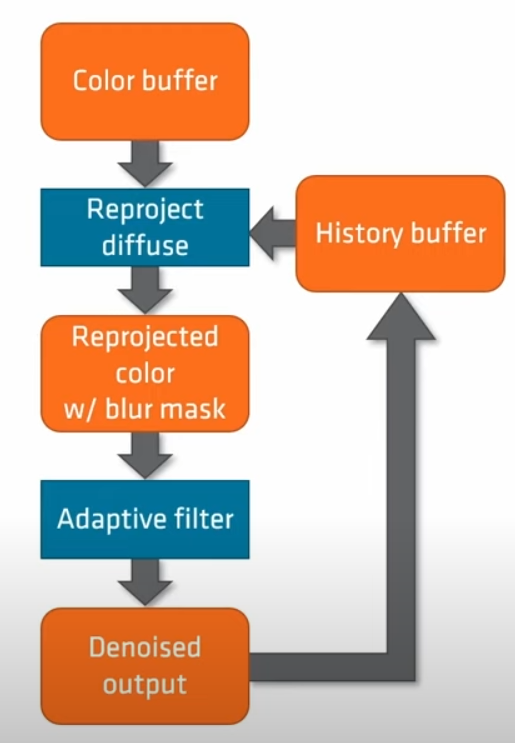
Denoising 部分完全依赖Temporal。在管线的循环中,我们保存前八帧的数据,越远的帧分辨率越低。每帧的分辨率保存到一个blur mask之中,用于做adaptive filter。当某一个像素 Temporal Filtering成功时,直接返回上一帧的数据;但是可能由于遮挡物移动导致重投影失败,这时就从前八帧数据中通过blur mask做adaptive filter。
5.3 Reaction to Light Change

使用较小的固定混合系数来将历史光照与新光照进行混合,这样做会使图像更加稳定,但是当光照剧烈变化时收敛速度很慢。

混合系数可以是变化的。引入方差和平均值来动态控制混合系数,上图为混合系数的可视化。

引入动态混合系数之后的结果。
6 Miscellanrous
6.1 Detials
- 球谐空间radiance计算和插值
- Screen Space GI and HBAO
- ……

6.2 Performance Results







6.3 Furture
- 整个场景还是偏暗
- Radiosity
- 目前还局限于平滑效果,引入BRDF波瓣采样来适配反射等
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!