GAMES202 Industrial Solution
本文最后更新于:6 个月前
目前工业界的一些主流做法
SVGF时空方差引导滤波器(Spatiotemporal Variance-Guided Filter)

SVGF和双边滤波很像,但是额外引入了方差因素和厚度。
双边滤波
SVGF改进了传统的双边滤波,并不是exp上作差取个高斯分布这么简单,考虑了三个因素:depth、normal和color。

对于深度depth,我们考虑屏幕中AB两点。二者处于一个平面上,按照直觉来说应该会互相影响很多,但是按照传统的双边滤波,深度做差值之后exp取负的差值指数,算下来二者之间的影响就很小了,这是因为我们只对深度进行简单的相减的话,没有考虑场景的几何因素。SVGF引入深度梯度来进一步计算权重。上图公式可以看出,舍弃了指数高斯分布,分子依旧是二者深度差,分母分为三个部分:
\(\sigma_z\):人为给定的控制指数衰减快慢的参数,调参用的
\(|\nabla z(p) \cdot(p-q)|\):点P的梯度方向向量与P和Q两点连线的点乘,数学意义就是二者连线的距离在梯度方向上的投影大小
ϵ:由于前二者乘积可能非常小甚至为零,这在分母上是非常危险的,因此引入一个很小的常数项确保分母不会为零
梯度乘积的详细几何意义:
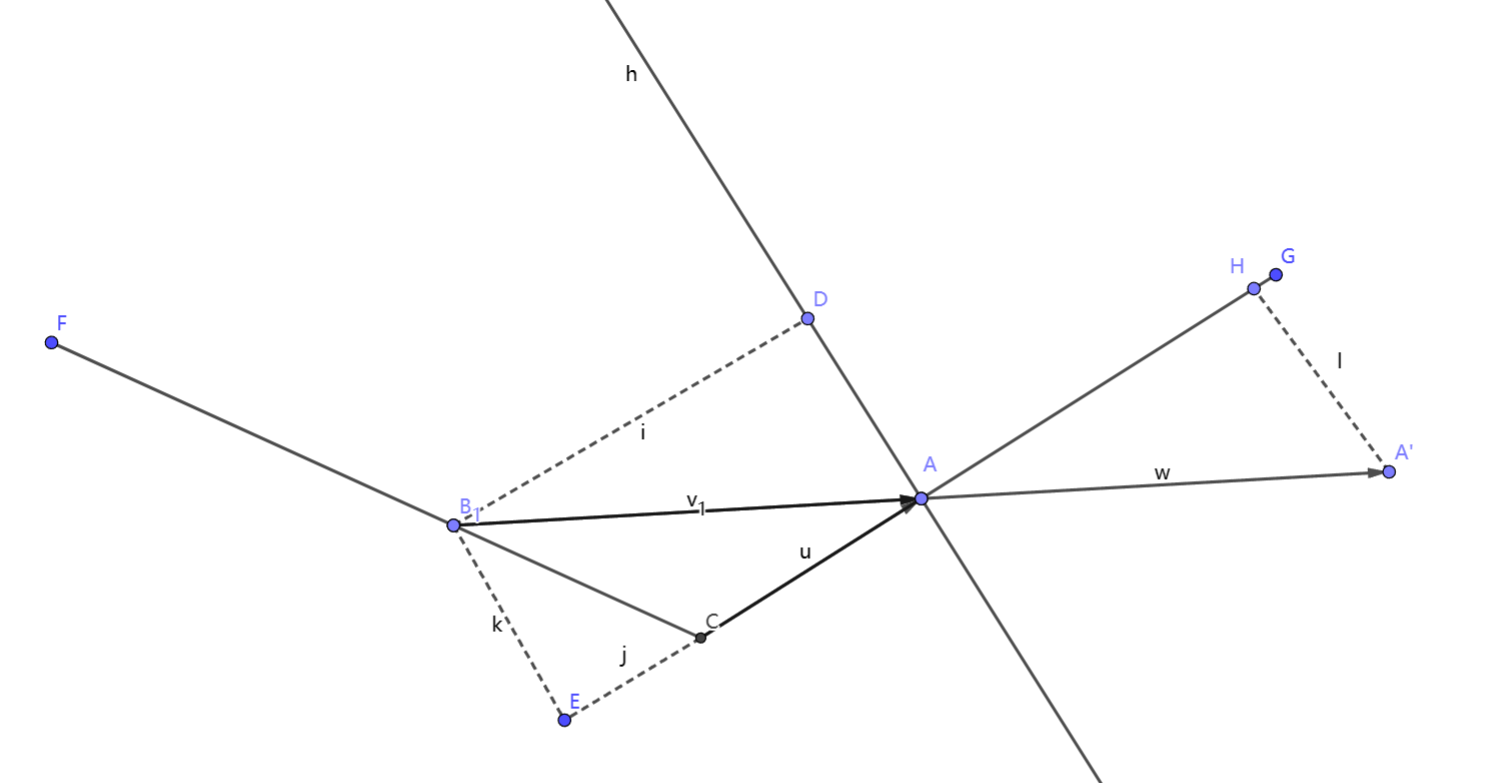
我们将三维转换到二维来解释。上图是某两个相交平面的俯视图,FC和GC是两个相交平面在俯视图上的投影线段,为了不失一般性,设定两个平面的夹角为钝角。点A是我们的shading point,现在我需要计算点B对点A的深度贡献。
按照SVGF的梯度深度做法,首先我们求得点A对于深度方向Z的梯度方向向量为\(\overrightarrow{CA}\)(因为平面是垂直与我们的,这个很容易理解),结合梯度算法\(|\nabla z(p) \cdot(p-q)|\)以及点乘的几何意义,实际上就是\(\overrightarrow{BA}\)在梯度方向\(\overrightarrow{CA}\)的投影长度,我们将\(\overrightarrow{BA}\)平移到\(\overrightarrow{AA^`}\),最终计算结果实际上就是线段AH的长度。从点B出发,向CA的垂线做垂线交于点D,向CA做垂线交于点E,我们很容易证明AH=BD=EA。我们从BD和EA上思考几何意义,可以发现:
对于BD,深度梯度算法实际上是点B到shading point A点梯度平面(切平面)法线的投影线段长度
对于EA,深度梯度算法实际上是先将点B投影到A点梯度平面(切平面),然后计算AB在梯度方向上的距离

对于normal,直接将两个normal点乘,指数上放了一个变量来控制权重大小。注意到有一些场景本身是有法线贴图或者AO贴图的,看起来很平的表面在法线贴图上两点可能法线差异很大,因此我们采用法线贴图扰动 或者AO处理之前的平滑的法线(类似于Gbuffer的normal)。

对于color,我们引入variance。通过Spatial ——Temporal——Spatial 三个步骤去计算variance。
- 在当前像素7*7的范围呢计算一次方差
- 通过motion vector找到上一帧的位置,平方相减再做一次方差
- 还不放心,最终计算的时候再在3*3的范围内再算一次方差,也就是公式里3X3的意义
公式分母上开了个根号,实际上参与计算的是标准差。其余参数和上文一个意思。注意这里参与计算的color不是shading color,而是最终color除以abedo得到的结果,我们叫做luminance,也可以理解为灰度。
RAE(Recurrent AutoEncoder)

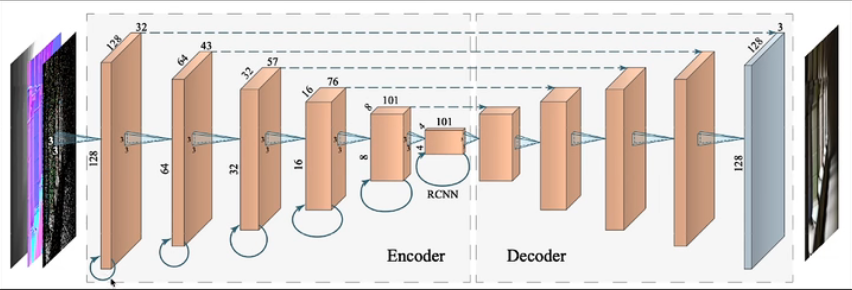
对RAE的介绍很少,它将denoising与神经网络结合,输入参数是原始图片和Gbuffer。由于神经网络每一层都会留下一些学习之后的数据,所以不需要motion vector,可以利用历史数据做到temporal的效果。
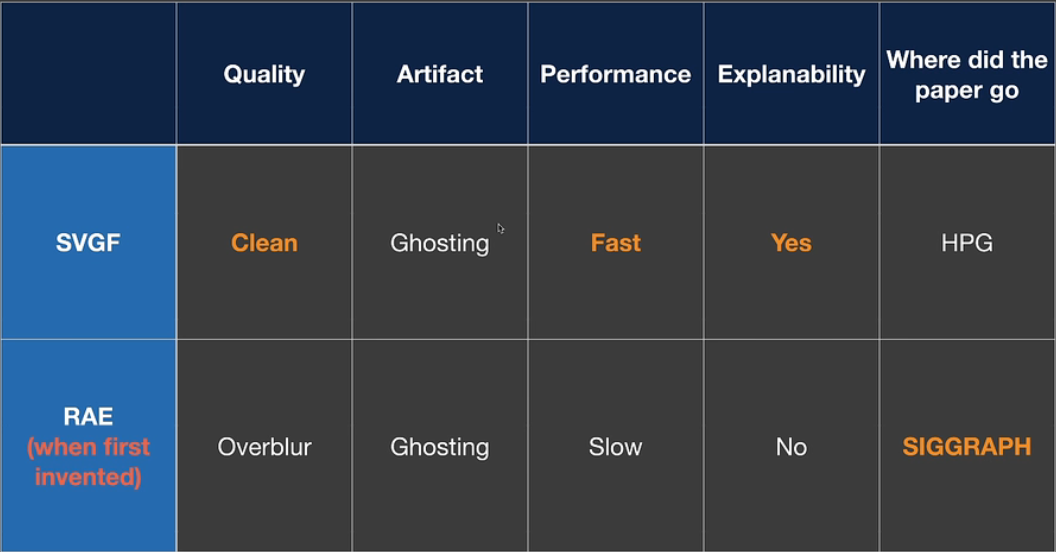
上图是二者的对比。但是RAE有明显的优点,就是对于SPP很多的情况下,SVGF计算量明显变多,但是不会影响RAE。
AA反走样(Anti-Aliasing)
TAA(Temporal Anti-Aliasing)
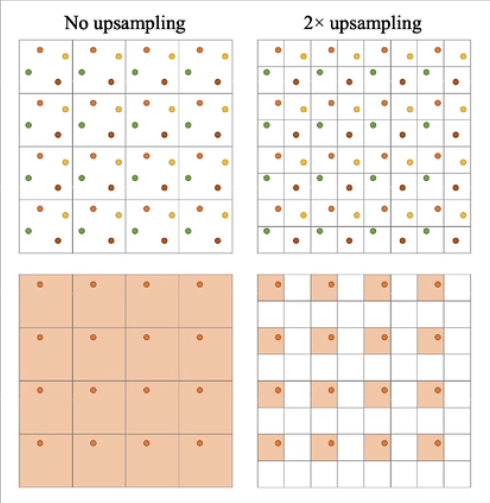
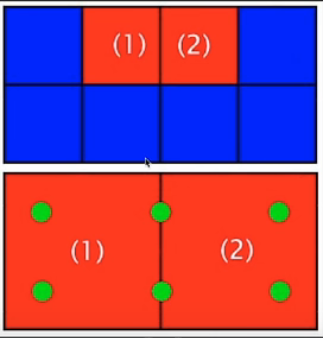
上文提到的temporal降噪,实际上是TAA的变体。temporal最开始是用来做抗锯齿的。我们知道消除锯齿的方法是增加采样点或者提高分辨率。TAA就是采用时域累积的思路做到的。通常像素表示的颜色是它中心点的颜色,但是这里我们不这么做。如上图,我们将一个像素区域分为四块,按顺序分别编号为1,2,3,4。从第一帧开始,我们规定每四帧为一组,每个像素按顺序分别从1,2,3,4四个块里读取颜色。例如第一帧每个像素都取左上角,第二帧每个像素都取右上角,第三帧都取左下角……四帧为一循环,最终当前帧的输出是历史三帧加当前帧颜色的混合值,这样就完成了一次2xTAA。对于静止画面直接采样就行,对于运动画面需要用到motion vector,失败的话就直接clamping。
TAA本质上就是把SSAA(SuperSampling)均摊到了好几帧去做,这样解决了SSAA太耗的问题。
MSAA(Multisampling)
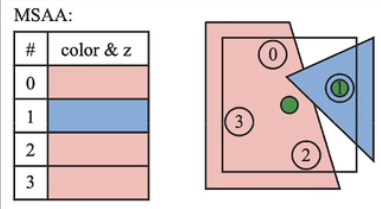
MSAA核心思路是Sample。对于2xMSAA来说,它将一个像素块分为四个部分,但是并不是一定同时计算四个color。它通过depth等信息对每个像素覆盖的mesh进行判断,例如上图0,2,3号位置被一个mesh覆盖,1号位置被另一个mesh覆盖,那么它将0,2,3三个位置拟合成一个点进行一次计算即可,本像素实际上只shading了两个color。还有一些进阶的方式,例如下图,中间有两个采样点可以被两个相邻像素共用,那么这两个像素只计算六个color即可,不用计算八个了。
SMAA(Enhanced Subpixel morphological AA)
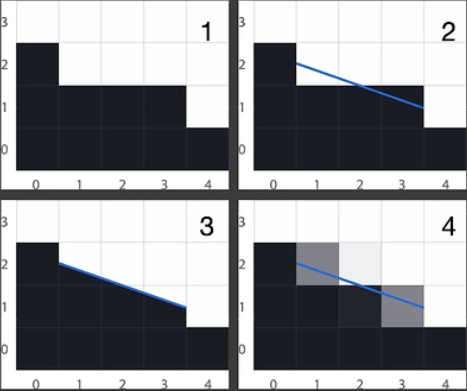
SMAA是从FXAA——MLAA——SMAA发展来的。对于图1的着色结果,SMAA首先对图像进行矢量化,找到待处理的边界,然后基于color覆盖率去进行均匀着色。
注意,Gbuffer是绝对不能AA的!
超分辨率

提到超分,就必须提到著名的DLSS技术。DLSS1.0是纯靠机器学习连蒙带猜的。但是上文我们提到的TAA技术其实就是一种超分辨率的方法,把一帧高分辨率的图片平摊到多帧去渲染然后整合。DLSS2.0就是这么做的。
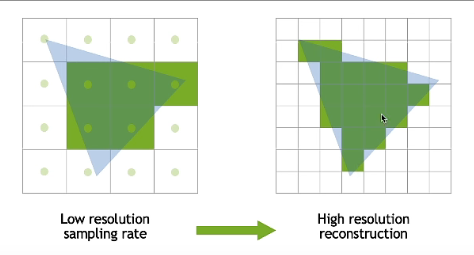
但是DLSS有一个严重的问题。上文我们提到在TAA中对于motion vector失效的地方,我们可以直接根据周围颜色clamp出一个值,反正最终都是混合输出的,影响不大。但是对于DLSS来说,超分需要对每个高分辨率的pixel都准确的赋值,直接clamp出来的值是不准确的,会让画面更糊,blur的很厉害。因此网络的主要任务就是提供对于历史帧Temporal的信息如何使用的方法。
Defferd Shading

传统光栅化流程中,首先将三角形组合成片段(fragments),然后在流水线中进行深度测试,shading然后pixel着色。由于光栅化是流水线形式的,fragments是一个一个送进深度测试的,最坏情况下场景中物体一个挡着一个,我把物体从远到进依次放入流水线去做深度测试,那么最终导致的结果就是我每个物体都需要shading一遍,但是实际上我只需要shading我能看到的物体就够了。
Defferd Shading就是用来解决这个问题的。我们对场景光栅化两次:
pass 1:我们仍旧按照传统光栅化流程将fragments送进流水线,但是只进行深度测试更新depth buffer,不做shading;
pass 2:再做一次光栅化,但是在深度测试中将fragment depth和pass 1中的depth buffer进行比较,太远的就直接干掉。
pass 1可以看作以相机为视角生成了一个shadow map。但是老问题,不能做半透明,AA也会出问题,TAA可以。
Many Light(多光源)
Tiled Shading
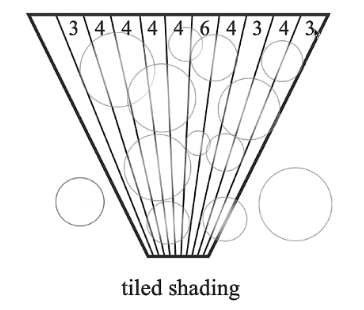
Tiled Shading应该是最原始的多光源处理方案了。本质上是从屏幕空间做的light culling(光源剔除)。
对于光源来说,由于光的强度可以近似看成按距离衰减,因此可以给光源近似加一个影响范围,在范围之外的不受这个光源影响。例如点光源近似为一个球体。
我们将屏幕分为很多个tile,例如32*32个像素为一个tile,转换到世界空间中,每个tile对应于一个视椎体体积。我们统计每个tile椎体被哪些光源影响并记录。在光栅化shading过程中,对应的tile中的fragment 只需要去trace影响本tile的光源即可,不需要遍历所有光源。
Clustered Shading
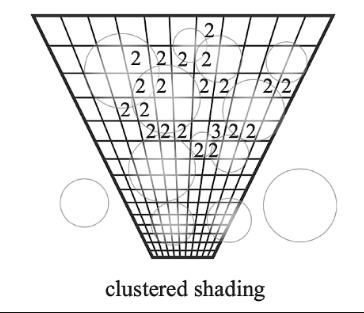
理解起来很简单,Tiled Shading是完全基于屏幕空间的,那么只要引入深度,屏幕空间就可以转换为世界空间。Clustered Shading在每个tile上引入了深度,就是将tile椎体又分成了由近到远的一段一段。每个段都判断自己与哪些光源相交。这样转换到世界空间后,每个fragment只需要trace本段内的光源即可,数量比之前整个椎体的少很多。
但是这种基于屏幕的culling方式需要每帧去更新。场景voxelize技术近年来应用十分广泛。我们可以引入体素化的方式在世界空间范围内进行light culling,对于全局光照技术十分契合。在某个十分聪明的GI上就是这么用的。(乐)
LOD(Level of Detail Solutions)(Cascaded)
LOD直译过来是多级细节的意思。分级的依据是距离。对于相机近的地方需要绘制的很精细,例如shadow、材质贴图、模型精度等精度很高,但是视椎体屏幕一个像素在世界空间的投影是越远越大的,你在很远的位置shading的很精细,返回屏幕上也就是几个像素的color而已,因此远处的物体的精度可以很低,需要的各种贴图资源精度也很低,这种技术就是LOD。LOD通常按照一个三角形最多覆盖一个像素来进行分级。
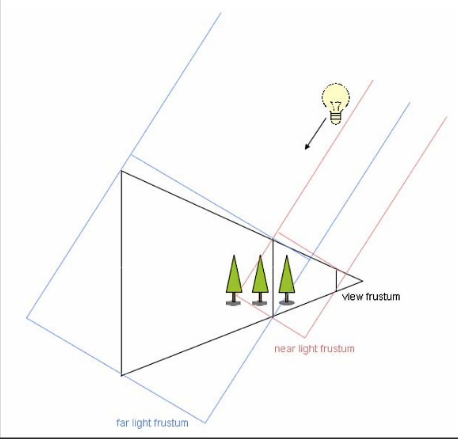
以shadowmap为例。shadowmap是从光源视角渲染出来的一张场景深度贴图,用来存储该光源能够直接照射到的位置相对于光源的深度信息。红色框离相机很近,shadowmap精度高,相应的蓝色框精度就低。我们注意到两个shadowmap直接有一个重叠,这是保证平滑的过渡,防止交界处出现artifact。
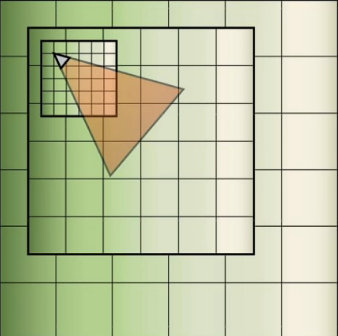
在LPV(Light Propagation Volumes)上道理也一样,多级volume可以加快光线的传播计算。
LOD的一些技术难点:
不同精度之间的平滑转换是很困难的,但是可以交给TAA来处理。
对于不同的几何精度如何衔接。例如近处的物体和地面精度和远处不是一个LOD Level,如何在mesh上连接起来。
由于对场景进行了几个精度的分级,把所有Level资源都缓存下来是很费的,如何合理地动态的对场景的这些资源进行调度和缓存。
用什么结构去表示这些多级的几何信息。可用Virtual Texture。
对于裁剪和剔除如何更好的适配。
UE5 Lumen GI

GAMES202出这期的时候UE5才出预览版。本文撰写到这里的时候版本已经更新到了5.2的预览版。Lumen已经和闫老师讲的有很大不同了,因此这里不多加赘述,网上有很多详细的技术解读。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!